機器學習:更多的數據總是優于更好的算法嗎?
 2023-07-10 02:49:46
2023-07-10 02:49:46

在機器學習中,更多的數據總是比更好的算法好嗎?對于Quora上的這個問題,Netflix公司工程總監Xavier Amatriain認為,很多時候增加更多的樣本到訓練集并不會提高模型的性能,而如果沒有合理的方法,數據就會成為噪音。他通過Netflix的實踐經驗推導出最終的結論:我們需要的是好的方法,來幫助我們理解如何解釋數據,模型,以及兩者的局限性,這都是為了得到最好的輸出。
在機器學習中,更多的數據總是比更好的算法好嗎?
不是這樣的。有時候更多的數據有用,有時它的作用不大。
為數據的力量辯護,也許最著名的是谷歌的研發總監Peter Norvig,他聲稱“我們沒有更好的算法。我們僅僅擁有更多的數據”。這句話通常是鏈接到文章《The Unreasonable Effectiveness of Data》,這篇文章也是Norvig自己寫的(雖然它的來源被放在IEEE收費專區,不過你應該能夠在網上找到pdf格式的原文檔)。更好的模型蓋棺定論是Norvig的語錄“所有模型都是錯的,無論如何你都不會需要他們的”被錯誤地引用之時(點擊這里查看作者澄清他是如何被錯誤引用的)。
Norvig等人的作用是指在他們的文章中,他們的觀點早在幾年前被微軟研究人員Banko和Brill在一篇著名的論文[2001]《Scaling to Very Very Large Corpora for Natural Language Disambiguation》中引用。在這篇論文中,作者給出了下圖。

該圖表明,對于給定的問題,迥然不同的算法執行結果幾乎是一樣的。然而,添加更多的樣本(單詞)到訓練集里面,可以單調增加模型的精度。
因此,在封閉的情況下,你可能會認為算法更重要。嗯…沒有這么快。事實是,Norvig的斷言以及Banko和Brill的論文都是正確的…在一個環境中。但是,他們現在再次被錯誤地引用到一些環境中,而這些環境與最初的環境是完全不同的。但是,為了搞明白為什么,我們需要了解一些技術。(我不打算在這篇文章中給出一個完整的機器學習教程。如果你不明白我下面將要做出的解釋,請閱讀我對《How do I learn machine learning?》的回答?
方差還是偏差?
基本的想法是,一個模型的可能表現不好存在兩種可能的(而且是幾乎相反的)原因。
在第一種情況下,對于我們擁有的數據量來說,我們所用的模型太復雜了。這是一種以高方差著稱的情形,其可以導致模型過擬合。我們知道,當訓練誤差遠低于測試誤差時,我們正面臨著一個高方差問題。高方差問題可以通過減少特征數量加以解決,是的,還有一種方法是通過增加數據點的數量。所以,什么樣的模型是Banko &Brill的觀點和Norvig的斷言可以處理的?是的,回答正確:高方差。在這兩種情況下,作者致力于語言模型,其中詞匯表中的大約每一個詞都具有特征。與訓練樣本相比,這有一些模型,它們具有許多特征。因此他們很有可能過擬合。是的,在這種情況下,添加更多的樣本將帶來很多幫助。
但是,在相反的情況下,我們可能有一個模型,它太簡單了以至于無法解釋我們擁有的數據。在這種情況下,以高偏差著稱,添加更多的數據不會帶來幫助。參見下面一個真實的在Netflix運行的系統的一個制表以及它的性能,同時我們添加更多的訓練樣本到里面去。
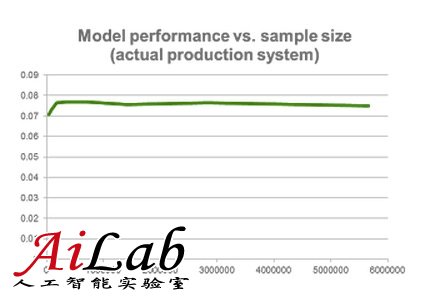
所以,更多的數據并不總是有幫助的。正如我們剛剛看到的,在許多情況下,增加更多的樣本到我們的訓練集并不會提高模型的性能。
多特征救援
如果你一直跟著我的節奏,到目前為止,你已經完成了理解高方差和高偏差問題的功課。你可能會認為我故意留下了一些東西要討論。是的,高偏差模型將不會受益于更多的訓練樣本,但是他們很可能受益于更多的特征。所以,到底這是不是都是關于增加“更多”數據的?好吧,再強調一次,這得視情況而定。
例如,在Netflix Prize的早期,有一個以評論額外特征的使用來解決問題的博客文章,它是由企業家和斯坦福大學教授Anand Rajaraman建立的。這個帖子解釋了一個學生團隊如何通過從IMDB添加內容特征來改善預測精度特性。

現在回想起來,很容易在批評后作出針對一個單一數據點的粗俗的過度泛化。更有甚者,后續文章提及SVD是一個“復雜”的算法,不值得一試,因為它限制了擴大更多的特征的能力。顯然,Anand的學生沒有贏得Netflix Prize,而且他們現在可能意識到SVD在獲獎作品中發揮著重要的作用。
事實上,許多團隊后來顯示,添加來自IMDB的內容特征等等到一個優化算法上幾乎沒有改善。Gravity team的一些成員,他們是Netflix Prize的最優秀的競爭者之一,發表了一篇詳細的論文,展示了將這些基于內容的特征添加到高度優化的協同過濾矩陣分解的方法沒有任何改善。這篇論文題為“Recommending New Movies: Even a Few Ratings Are More Valuable Than metadata”。

為了公平起見,論文的標題也是一個過度泛化。基于內容的特征(或一般的不同特征)在許多情況下可以提高精確度。但是,你明白我的意思:更多的數據并不總是有幫助的。
更好的數據!=更多的數據
在我看來,重要的是要指出,更好的數據始終更好。對此沒有反對意見。所以任何你能夠直接針對你的數據進行“改善”的努力始終是一項很好的投資。問題是,更好的數據并不意味著更多的數據。事實上,有時這可能意味著少!
想想數據清理或異常值去除,就當是我的觀點一個微不足道的說明。但是,還有許多其他的更微妙的例子。例如,我已經看到人們投入大量的精力到Matrix Factorization,而真相是,他們可能通過采樣數據以及得到非常相似的結果獲得認可。事實上,做某種形式的智能人口抽樣的正確的方式(例如使用分層抽樣)可以讓你得到比使用整個未過濾得的數據集更好的結果。
科學方法的終結?
當然,每當有一個關于可能的范式的變化激烈的爭論,就會有像Malcolm Gladwell 和 Chris Anderson這樣的人以此謀生甚至未曾認真思考(不要誤會我的意思,我是他們倆的粉絲,我讀過他們的很多書)。在這種情況下,Anderson挑選了Norvig的一些評論,并錯誤地在一篇文章中引用,該文章的標題為:“The End of Theory: The Data Deluge Makes the Scientific Method Obsolete”。

這篇文章闡述了幾個例子,它們講的是豐富的數據如何幫助人們和企業決策甚至無需理解數據本身的含義。正如Norvig在他的辯駁中自己指出的問題,Anderson有幾個觀點是正確的,但是很難實現。而且結果是一組虛假陳述,從標題開始:海量數據并未淘汰科學方法。我認為這恰恰相反。
數據沒有合理的方法=噪音
所以,我是在試圖制造大數據革命只是炒作的言論嗎?不可能。有更多的數據,無論是更多的例子樣本或更多的特征,都是一種幸事。數據的可用性使得更多更好的見解和應用程序成為可能。更多的數據的確帶來了更好的方法。更重要的是,它需要更好的方法。

綜上所述,我們應該不理會過分簡單的意見,它們所宣揚的是理論或者模型的無用性,或者數據在其他方面的成功的可能性。盡可能多的數據是必要的,所以就需要好的模型和理論來解釋它們。但是,總的來說,我們需要的是好的方法,來幫助我們理解如何解釋數據,模型,以及兩者的局限性,這都是為了得到最好的輸出。
換句話說,數據固然重要,但若沒有一個合理的的方法,數據將會成為噪音。