騰訊深度學習平臺亮相機器學習頂級會議ICML2014
 2023-07-10 00:41:00
2023-07-10 00:41:00

深度學習是近年機器學習領域的重大突破,有著廣泛的應用前景。隨著Google公開Google Brain計劃,業界對深度學習的熱情高漲。百度成立深度學習研究院,騰訊也啟動了深度學習的研究。騰訊在深度學習領域持續投入,獲得了實際落地的產出。本文是騰訊深度學習系列文章的第一篇。我們準備了四篇文章,闡述深度學習的原理和在騰訊的實踐。
2014年6月22日,騰訊深度學習平臺(Tencent Deep Learning Platform)于國際機器學習領域頂級會議ICML2014上首次公開亮相,揭秘了騰訊深度學習平臺的目標和技術路線,及其微信語音識別、微信圖像識別、廣點通廣告推薦等應用場景。
騰訊深度學習平臺包括深度神經網絡(Deep Neural Networks,DNN)的GPU數據并行框架,深度卷積神經網絡(Deep Convolutional Neural Networks,CNN)的GPU數據并行和模型并行框架,以及DNN CPU集群框架。上述框架實現了深度學習的共性需求,減少新算法開發量。框架通過并行加速,加速深度學習訓練。
騰訊深度學習平臺的DNN GPU數據并行框架,在單機6 GPU卡配置下獲得相比單卡4.6倍的加速,可在數日內完成數十億高維度訓練樣本的DNN模型訓練。同時通過算法優化,在模型訓練提速的同時,提升了模型的分類準確度10%以上。基于此DNN框架,微信語音識別業務得到進一步完善,已于2014年初全量上線微信語音輸入和語音開放平臺。深度學習平臺的CNN模型并行和數據并行框架,在單機4 GPU卡配置下,獲得了相比單卡2.52倍的加速,這一指標處于國際領先水平。基于CNN并行框架中的模型并行,圖像業務能夠支持更大規模圖像分類模型,在ImageNet 2012數據集中獲得了87%的top5準確率,處于國際先進水平。此外,騰訊深度學習平臺提供了DNN CPU集群框架,支持超大規模深度神經網絡訓練。

圖1:騰訊深度學習平臺在ICML2014的展區
深度學習是近年來機器學習領域最令人矚目的方向。自2006年深度學習界泰斗Geoffrey Hinton在Science雜志上發表Deep Belief Networks的論文后,重新激活了神經網絡的研究,開啟了深度神經網絡的新時代。學術界和工業界對深度學習熱情高漲,并逐漸在語音識別、圖像識別、自然語言處理等領域獲得突破性進展。深度學習在語音識別領域獲得相對20%到30%的準確率提升,突破了近十年的瓶頸。2012年圖像識別領域在ImageNet圖像分類競賽中取得了85%的top5準確率,相比前一年74%的準確率有里程碑式的提升,并進一步在2013年獲得89%的準確率。目前Google、Facebook、Microsoft、IBM等國際巨頭,以及國內百度、阿里巴巴等互聯網巨頭爭相布局深度學習。
深度學習通過構建深層神經網絡,來模擬人類大腦的工作原理。如圖2所示,深層神經網絡由一個輸入層,數個隱層,以及一個輸出層構成。每層有若干個神經元,神經元之間有連接權重。每個神經元模擬人類的神經細胞,而結點之間的連接模擬神經細胞之間的連接。
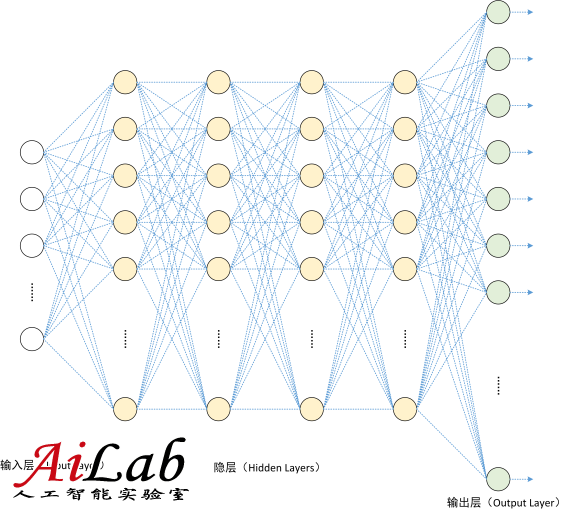
圖2:深度神經網絡的結構
但是,深度神經網絡面臨巨大的挑戰。
首先,深度神經網絡模型復雜,訓練數據多,計算量大。一方面,DNN需要模擬人腦的計算能力,而人腦包含100多億個神經細胞,這要求DNN中神經元多,神經元間連接數量也相當驚人。從數學的角度看,DNN中每個神經元都包含數學計算(如Sigmoid、ReLU或者Softmax函數),需要估計的參數量也極大。語音識別和圖像識別應用中,神經元達數萬個,參數數千萬,模型復雜導致計算量大。另一方面,DNN需要大量數據才能訓練出高準確率的模型。DNN參數量大,模型復雜,為了避免過擬合,需要海量訓練數據。兩方面因素疊加,導致訓練一個模型耗時驚人。以語音識別為例,目前業界通常使用樣本量達數十億,以CPU單機需要數年才能完成一次訓練。
其次,深度神經網絡訓練收斂難,需要反復多次實驗。深度神經網絡是非線性模型,其代價函數是非凸函數,容易收斂到局部最優解。同時,深度神經網絡的模型結構、輸入數據處理方式、權重初始化方案、參數配置、激活函數選擇、權重優化方法等均可能對最終效果有較大影響。另外,深度神經網絡的數學基礎研究稍顯不足。雖然可以通過限制性波爾茲曼機(Restricted Boltzmann Machines,RBMs)等減少陷入局部最優的風險,但仍然不是徹底的解決方案,仍然需要在實際使用深度神經網絡解決問題的時候,合理的利用海量數據,合理的選擇優化方式。上述原因導致需要技巧、經驗,基于大量實驗來訓練出一個效果好的模型。
面對機遇和挑戰,騰訊在2013年初,由WXG微信技術架構部聯合TEG數據平臺部啟動了深度學習的合作研究。微信技術架構部完成了DNN的單機多GPU模型并行訓練框架,數據平臺部著力打造DNN的CPU集群訓練框架。2013年5月,基于DNN訓練的語音業務正式上線。隨后以數據平臺部為主,融合雙方優勢,開發出升級版的DNN GPU數據并行框架,以及全新的CNN GPU模型并行和數據并行訓練框架,打造了統一的騰訊深度學習平臺。2014年初開始,全面應用于語音識別、圖像識別、廣告推薦等應用領域。騰訊深度學習平臺致力于通過并行技術加速訓練,并提供并行框架和算法以簡化算法工程師的工作。
騰訊深度學習平臺以GPU服務器為主,每臺服務器配置4或者6塊Nvidia Tesla系列高端科學計算用GPU卡。利用每塊GPU卡2000多個流處理器的強大計算能力,并實現多GPU卡并行以加速訓練。
騰訊深度學習平臺重點研究多GPU卡的并行化技術,完成DNN的數據并行框架,以及CNN的模型并行和數據并行框架。數據并行和模型并行是Google分布式大神Jeff Dean和深度學習大佬Andrew Ng在2012年NIPS會議上發表的DistBelief論文中針對深度學習的CPU集群框架提出的定義。數據并行指將訓練數據劃分為多份,每份數據有一個模型實例進行訓練,再將多個模型實例產生的梯度合并后更新模型。模型并行指將模型劃分為多個分片,每個分片在一臺服務器,全部分片協同對一份訓練數據進行訓練。我們學習并借鑒了這兩種并行方式,并成功應用于單機多GPU卡的并行。
DNN的數據并行框架通過同步隨機梯度下降進行訓練。數據并行訓練中,每個GPU卡各自訓練,并各自產生一份梯度值,然后進行參數交換。圖3展示了參數交換過程。每臺GPU服務器配置6塊GPU卡,其中四塊通過樹狀的PCIe連接,并與另外兩塊GPU卡通過IOH連接。參數交換過程從邏輯上看,梯度收集階段將全部梯度值累加起來,然后應用到當前模型以更新參數得到新模型,最后在模型分發階段將新模型下發給全部GPU卡。采用數據并行后,相對于單卡訓練過程,關鍵的問題是參數交換過程引入額外時間消耗,拖累了并行性能,使得加速比很難提高。我們通過一個精心設計的拓撲完成參數交換,提升整體性能。此外,我們采用近似的自適應學習率算法,使得支持自適應學習率所需交換的數據量降低了一個數量級。
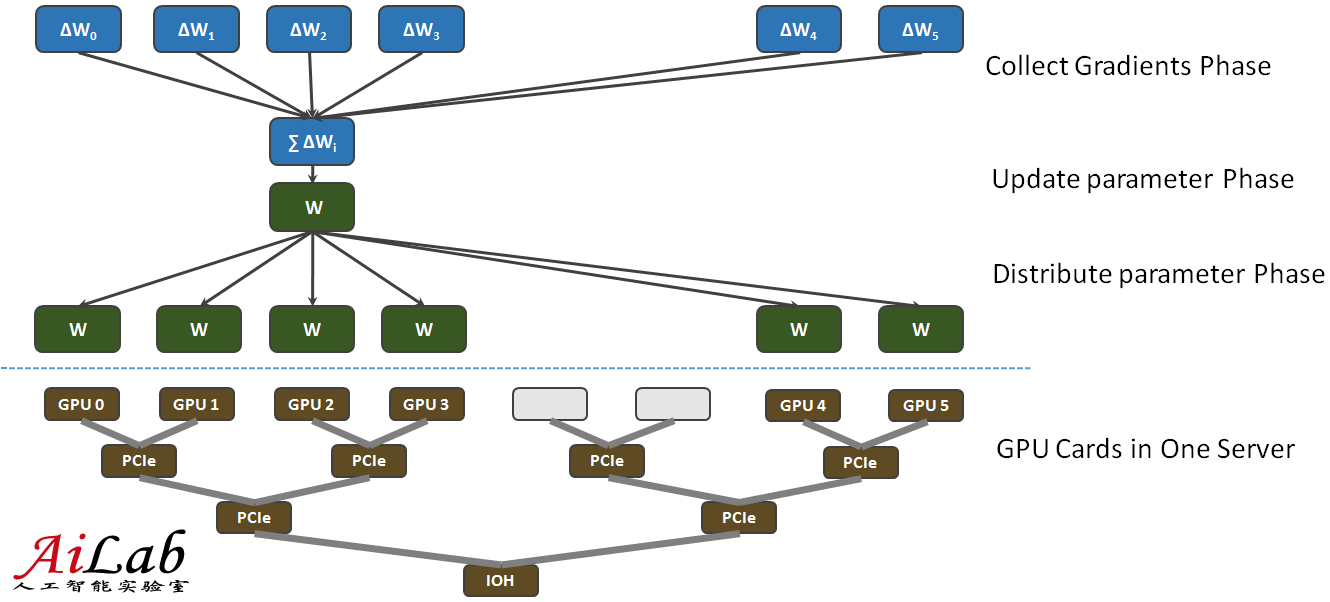
圖3:DNN GPU框架數據并行的參數交換過程
DNN的數據并行框架在微信語音識別中得到應用。微信中語音識別功能的入口是語音輸入法、語音開放平臺以及長按語音消息轉文本等。對微信語音識別任務,通過騰訊深度學習平臺,識別準確率獲得了極大的提升,目前識別能力已經躋身業界一流水平。同時可以滿足語音業務海量的訓練樣本需求,通過縮短模型更新周期,使得微信語音業務可以及時滿足各種新業務需求。
卷積神經網絡CNN的模型并行和數據并行框架的結構如下圖所示:

圖4:CNN GPU框架的模型并行和數據并行架構
CNN模型并行和數據并行框架對GPU卡分組,組內兩個GPU卡做模型并行,組間做數據并行。如上圖所示,4個GPU卡分成Worker Group 0和1。組內兩卡各持有CNN模型的一部分,稱為partition,協作完成單個模型的訓練。模型并行中,卡間數據傳輸通過引入Transfer Layer透明的完成。組間數據并行按同步隨機梯度下降進行訓練,并采用精巧的拓撲完成參數交換,但注意只有各組內屬于同一個partition的數據各自交換,即圖中GPU0和GPU2、GPU1和GPU3分別進行參數交換。引入數據并行和模型并行后,從磁盤讀取訓練數據,訓練數據預處理,CNN訓練分別占用磁盤、CPU、GPU資源,且均耗時較大。因此,我們引入流水線,使得磁盤、CPU、GPU資源可以同時得到利用,提升整體性能。
CNN數據并行和模型并行框架已在圖像識別應用中初見成效。針對Hinton在2012年獲得ImageNet競賽冠軍用的網絡,我們取得了兩卡模型并行1.71倍加速比,4 GPU卡數據并行加模型并行時比單卡2.52倍的加速比,處于國際領先水平。通過CNN并行框架的模型并行,單個GPU上CNN網絡占用的GPU顯存從3.99 GB減少到2.15 GB,使得可以訓練更大規模的圖像分類模型。通過模型并行獲得ImageNet 2012數據集87%的top5準確率,處于國際先進水平。CNN并行訓練框架在微信圖像業務中得到應用,圖像識別,圖像檢索,人臉識別,OCR識別等,都已嘗試接入本框架。同時數據平臺部支持的廣點通廣告推薦也開始應用探索。

圖5:CNN GPU框架對Hinton的網絡在ImageNet 2012的并行加速性能
DNN CPU集群框架實現基于CPU集群的數據并行和模型并行,其總體架構如下圖所示:

圖6:DNN CPU集群框架總體架構
DNN CPU集群框架提供Vertex+Message的API,實現Bulk Synchronous Parallel(BSP)模式。每次DNN訓練作業作為一個DNN Job,其執行包含多個迭代,用戶通過Client工具提交DNN Job。DNN Master負責任務調度,將訓練數據分發到不同的Worker Group進行訓練,并完成任務的failover等,以支持數據并行。Master將DNN Job的狀態變化通過LogStore系統同步到數據庫,便于從WebUI展示全部作業狀態。此外,Master負責Counter的收集,并在WebUI上可視化展示。每個Worker Group中有1個Coordinator協調全部Worker完成模型并行,而Worker完成具體訓練任務。模型通過參數服務器Parameter Server劃分,并可靠存儲在分布式文件系統中。在微信語音業務中,證明DNN CPU集群可取得與GPU相當的訓練結果,而且CPU集群訓練和GPU訓練框架有互補性。
經過一年多的沉淀,深度學習在騰訊產生了落地的成果。騰訊深度學習平臺逐步成型,形成了包括DNN GPU數據并行框架,CNN GPU模型并行和數據并行框架,以及DNN CPU集群模型并行和數據并行框架。上述框架實現了深度學習的共性需求,大幅節約算法開發時間。框架通過數據并行和模型并行,解決了深度學習耗時冗長的問題,成為深度學習研究的有效助力。騰訊深度學習平臺在GPU加速性能上已達到國際先進水平,并提交了兩項并行加速的專利。目前,騰訊深度學習平臺已在微信語音識別、微信圖像識別中得到深入應用,有效支持了產品,此外,在廣告推薦及個性化推薦等領域,也正在積極探索和實驗中。