【深度學習系列】CNN模型的可視化
 2023-07-10 00:53:54
2023-07-10 00:53:54

大家都了解卷積神經網絡CNN,但是對于它在每一層提取到的特征以及訓練的過程可能還是不太明白,所以這篇主要通過模型的可視化來神經網絡在每一層中是如何訓練的。我們知道,神經網絡本身包含了一系列特征提取器,理想的feature map應該是稀疏的以及包含典型的局部信息。通過模型可視化能有一些直觀的認識并幫助我們調試模型,比如:feature map與原圖很接近,說明它沒有學到什么特征;或者它幾乎是一個純色的圖,說明它太過稀疏,可能是我們feature map數太多了(feature_map數太多也反映了卷積核太小)。可視化有很多種,比如:feature map可視化、權重可視化等等,我以feature map可視化為例。
模型可視化
因為我沒有搜到用paddlepaddle在imagenet 1000分類的數據集上預訓練好的googLeNet inception v3,所以用了keras做實驗,以下圖作為輸入:
輸入圖片
北汽紳寶D50:

feature map可視化
取網絡的前15層,每層取前3個feature map。
北汽紳寶D50 feature map:

從左往右看,可以看到整個特征提取的過程,有的分離背景、有的提取輪廓,有的提取色差,但也能發現10、11層中間兩個feature map是純色的,可能這一層feature map數有點多了,另外北汽紳寶D50的光暈對feature map中光暈的影響也能比較明顯看到。
Hypercolumns
通常我們把神經網絡最后一個fc全連接層作為整個圖片的特征表示,但是這一表示可能過于粗糙(從上面的feature map可視化也能看出來),沒法精確描述局部空間上的特征,而網絡的第一層空間特征又太過精確,缺乏語義信息(比如后面的色差、輪廓等),于是論文《Hypercolumns for Object Segmentation and Fine-grained Localization》提出一種新的特征表示方法:Hypercolumns——將一個像素的 hypercolumn 定義為所有 cnn 單元對應該像素位置的激活輸出值組成的向量),比較好的tradeoff了前面兩個問題,直觀地看如圖:
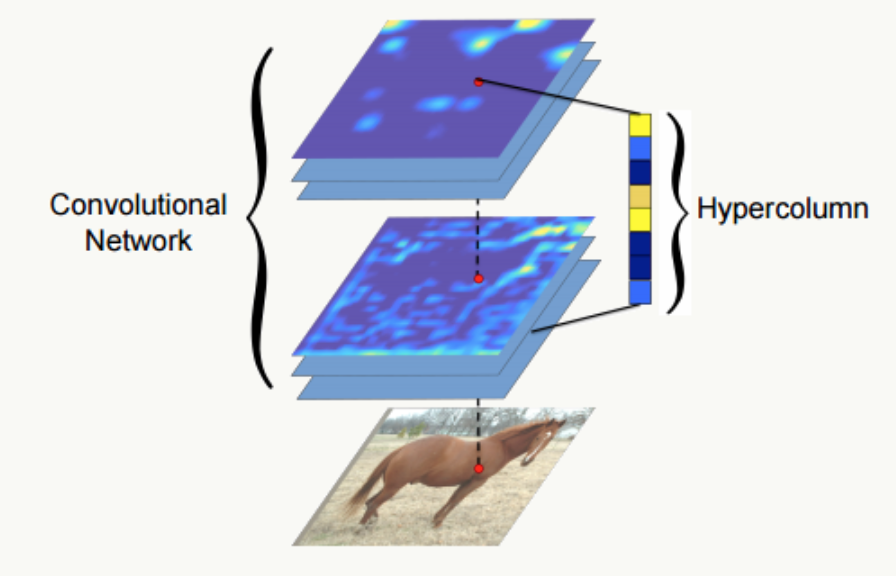
把北汽紳寶D50 第1、4、7層的feature map以及第1, 4, 7, 10, 11, 14, 17層的feature map分別做平均,可視化如下:

代碼實踐(關注博客園專欄作者:Charlotte77 http://www.cnblogs.com/charlotte77 查看源代碼)


總結
還有一些網站做的關于CNN的可視化做的非常不錯,譬如這個網站:http://shixialiu.com/publications/cnnvis/demo/,大家可以在訓練的時候采取不同的卷積核尺寸和個數對照來看訓練的中間過程。最近PaddlePaddle也開源了可視化工具VisaulDL,下篇文章我們講講paddlepaddle的visualDL和tesorflow的tensorboard。