【深度學習系列】用PaddlePaddle和Tensorflow實現經典CNN網絡GoogLeNet
 2023-07-10 00:54:29
2023-07-10 00:54:29

前面講了LeNet、AlexNet和Vgg,這周來講講GoogLeNet。GoogLeNet是由google的Christian Szegedy等人在2014年的論文《Going Deeper with Convolutions》提出,其最大的亮點是提出一種叫Inception的結構,以此為基礎構建GoogLeNet,并在當年的ImageNet分類和檢測任務中獲得第一,ps:GoogLeNet的取名是為了向YannLeCun的LeNet系列致敬。
(本系列所有代碼均在github:https://github.com/huxiaoman7/PaddlePaddle_code)
關于深度網絡的一些思考
在本系列最開始的幾篇文章我們講到了卷積神經網絡,設計的網絡結構也非常簡單,屬于淺層神經網絡,如三層的卷積神經網絡等,但是在層數比較少的時候,有時候效果往往并沒有那么好,在實驗過程中發現,當我們嘗試增加網絡的層數,或者增加每一層網絡的神經元個數的時候,對準確率有一定的提升,簡單的說就是增加網絡的深度與寬度,但這樣做有兩個明顯的缺點:
-
更深更寬的網絡意味著更多的參數,提高了模型的復雜度,從而大大增加過擬合的風險,尤其在訓練數據不是那么多或者某個label訓練數據不足的情況下更容易發生;
-
增加計算資源的消耗,實際情況下,不管是因為數據稀疏還是擴充的網絡結構利用不充分(比如很多權重接近0),都會導致大量計算的浪費。
解決以上兩個問題的基本方法是將全連接或卷積連接改為稀疏連接。不管從生物的角度還是機器學習的角度,稀疏性都有良好的表現,回想一下在講AlexNet這一節提出的Dropout網絡以及ReLU激活函數,其本質就是利用稀疏性提高模型泛化性(但需要計算的參數沒變少)。
簡單解釋下稀疏性,當整個特征空間是非線性甚至不連續時:
-
學好局部空間的特征集更能提升性能,類似于Maxout網絡中使用多個局部線性函數的組合來擬合非線性函數的思想;
-
假設整個特征空間由N個不連續局部特征空間集合組成,任意一個樣本會被映射到這N個空間中并激活/不激活相應特征維度,如果用C1表示某類樣本被激活的特征維度集合,用C2表示另一類樣本的特征維度集合,當數據量不夠大時,要想增加特征區分度并很好的區分兩類樣本,就要降低C1和C2的重合度(比如可用Jaccard距離衡量),即縮小C1和C2的大小,意味著相應的特征維度集會變稀疏。
不過尷尬的是,現在的計算機體系結構更善于稠密數據的計算,而在非均勻分布的稀疏數據上的計算效率極差,比如稀疏性會導致的緩存miss率極高,于是需要一種方法既能發揮稀疏網絡的優勢又能保證計算效率。好在前人做了大量實驗(如《On Two-Dimensional Sparse Matrix Partitioning: Models, Methods, and a Recipe》),發現對稀疏矩陣做聚類得到相對稠密的子矩陣可以大幅提高稀疏矩陣乘法性能,借鑒這個思想,作者提出Inception的結構。
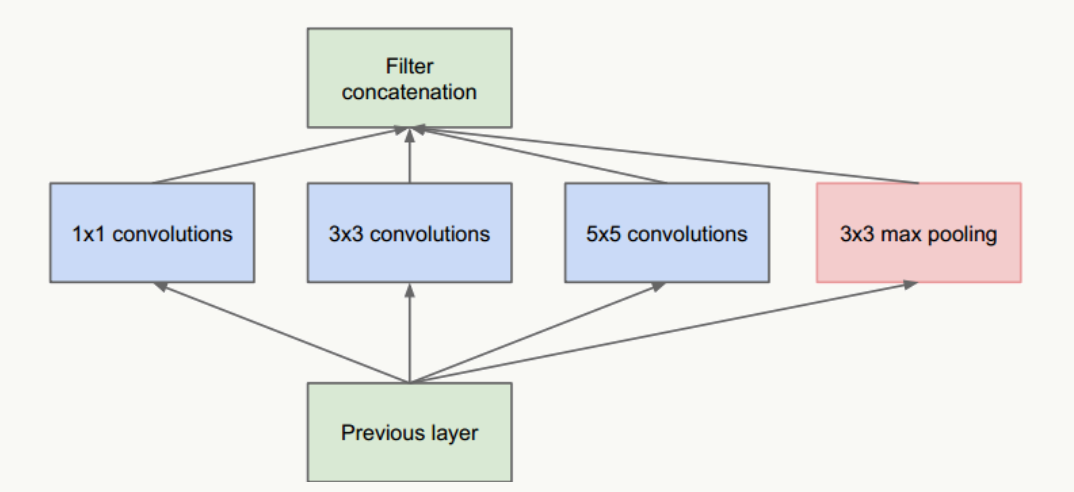
圖1 Inception結構
-
把不同大小卷積核抽象得到的特征空間看做子特征空間,每個子特征空間都是稀疏的,把這些不同尺度特征做融合,相當于得到一個相對稠密的空間;
-
采用1×1、3×3、5×5卷積核(不是必須的,也可以是其他大小),stride取1,利用padding可以方便的做輸出特征維度對齊;
-
大量事實表明pooling層能有效提高卷積網絡的效果,所以加了一條max pooling路徑;
-
這個結構符合直觀理解,視覺信息通過不同尺度的變換被聚合起來作為下一階段的特征,比如:人的高矮、胖瘦、青老信息被聚合后做下一步判斷。
這個網絡的最大問題是5×5卷積帶來了巨大計算負擔,例如,假設上層輸入為:28×28×192:
-
直接經過96個5×5卷積層(stride=1,padding=2)后,輸出為:28×28×96,卷積層參數量為:192×5×5×96=460800;
-
借鑒NIN網絡(Network in Network,后續會講),在5×5卷積前使用32個1×1卷積核做維度縮減,變成28×28×32,之后經過96個5×5卷積層(stride=1,padding=2)后,輸出為:28×28×96,但所有卷積層的參數量為:192×1×1×32+32×5×5×96=82944,可見整個參數量是原來的1/5.5,且效果上沒有多少損失。
新網絡結構為
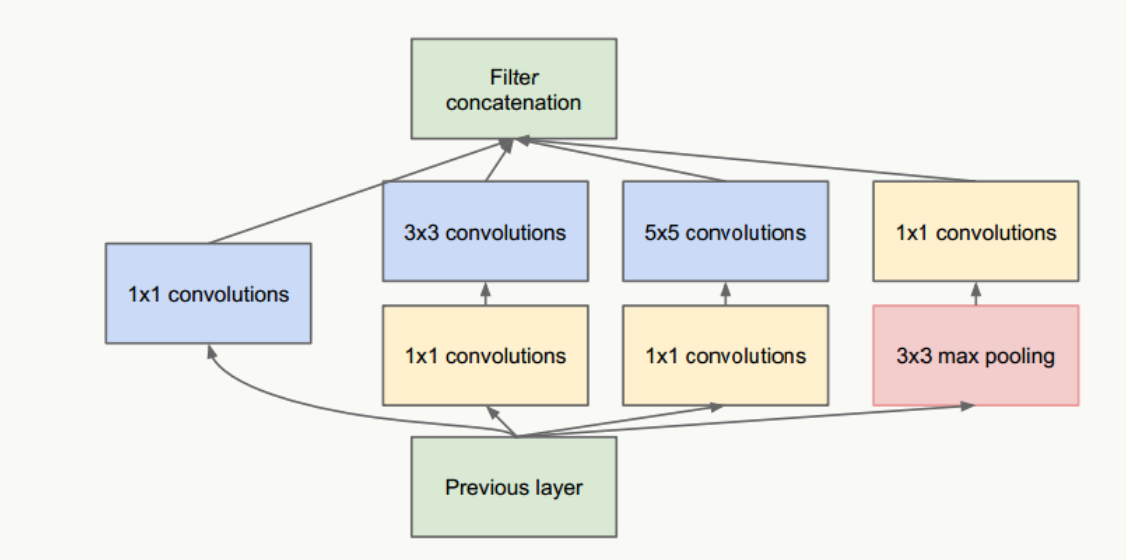
圖2 新Inception結構
GoogLeNet網絡結構
利用上述Inception模塊構建GoogLeNet,實驗表明Inception模塊出現在高層特征抽象時會更加有效(我理解由于其結構特點,更適合提取高階特征,讓它提取低階特征會導致特征信息丟失),所以在低層依然使用傳統卷積層。整個網路結構如下:

圖3 GoogLeNet網絡結構

圖4 GoogLeNet詳細網絡結構示意圖
網絡說明:
-
所有卷積層均使用ReLU激活函數,包括做了1×1卷積降維后的激活;
-
移除全連接層,像NIN一樣使用Global Average Pooling,使得Top 1準確率提高0.6%,但由于GAP與類別數目有關系,為了方便大家做模型fine-tuning,最后加了一個全連接層;
-
與前面的ResNet類似,實驗觀察到,相對淺層的神經網絡層對模型效果有較大的貢獻,訓練階段通過對Inception(4a、4d)增加兩個額外的分類器來增強反向傳播時的梯度信號,但最重要的還是正則化作用,這一點在GoogLeNet v3中得到實驗證實,并間接證實了GoogLeNet V2中BN的正則化作用,這兩個分類器的loss會以0.3的權重加在整體loss上,在模型inference階段,這兩個分類器會被去掉;
-
用于降維的1×1卷積核個數為128個;
-
全連接層使用1024個神經元;
-
使用丟棄概率為0.7的Dropout層;
網絡結構詳細說明:
輸入數據為224×224×3的RGB圖像,圖中"S"代表做same-padding,"V"代表不做。
-
C1卷積層:64個7×7卷積核(stride=2,padding=3),輸出為:112×112×64;
-
P1抽樣層:64個3×3卷積核(stride=2),輸出為56×56×64,其中:56=(112-3+1)/2+1
-
C2卷積層:192個3×3卷積核(stride=1,padding=1),輸出為:56×56×192;
-
P2抽樣層:192個3×3卷積核(stride=2),輸出為28×28×192,其中:28=(56-3+1)/2+1,接著數據被分出4個分支,進入Inception (3a)
-
Inception (3a):由4部分組成
-
64個1×1的卷積核,輸出為28×28×64;
-
96個1×1的卷積核做降維,輸出為28×28×96,之后128個3×3卷積核(stride=1,padding=1),輸出為:28×28×128
-
16個1×1的卷積核做降維,輸出為28×28×16,之后32個5×5卷積核(stride=1,padding=2),輸出為:28×28×32
-
192個3×3卷積核(stride=1,padding=1),輸出為28×28×192,進行32個1×1卷積核,輸出為:28×28×32
最后對4個分支的輸出做“深度”方向組合,得到輸出28×28×256,接著數據被分出4個分支,進入Inception (3b);
-
-
Inception (3b):由4部分組成
-
128個1×1的卷積核,輸出為28×28×128;
-
128個1×1的卷積核做降維,輸出為28×28×128,進行192個3×3卷積核(stride=1,padding=1),輸出為:28×28×192
-
32個1×1的卷積核做降維,輸出為28×28×32,進行96個5×5卷積核(stride=1,padding=2),輸出為:28×28×96
-
256個3×3卷積核(stride=1,padding=1),輸出為28×28×256,進行64個1×1卷積核,輸出為:28×28×64
最后對4個分支的輸出做“深度”方向組合,得到輸出28×28×480;
后面結構以此類推。
-
用PaddlePaddle實現GoogLeNet
1.網絡結構googlenet.py
在PaddlePaddle的models下面,有關于GoogLeNet的實現代碼,大家可以直接學習拿來跑一下:

2.訓練模型

3.運行方式
1 python train.py googlenet
其中最后的googlenet是可選的網絡模型,輸入其他的網絡模型,如alexnet、vgg3、vgg6等就可以用不同的網絡結構來訓練了。
用Tensorflow實現GoogLeNet
tensorflow的實現在models里有非常詳細的代碼,這里就不全部貼出來了,大家可以在models/research/slim/nets/里詳細看看,關于InceptionV1~InceptionV4的實現都有。
ps:這里的slim不是tensorflow的contrib下的slim,是models下的slim,別弄混了,slim可以理解為Tensorflow的一個高階api,在構建這些復雜的網絡結構時,可以直接調用slim封裝好的網絡結構就可以了,而不需要從頭開始寫整個網絡結構。關于slim的詳細大家可以在網上搜索,非常方便。
總結
其實GoogLeNet的最關鍵的一點就是提出了Inception結構,這有個什么好處呢,原來你想要提高準確率,需要堆疊更深的層,增加神經元個數等,堆疊到一定層可能結果的準確率就提不上去了,因為參數更多了啊,模型更復雜,更容易過擬合了,但是在實驗中轉向了更稀疏但是更精密的結構同樣可以達到很好的效果,說明我們可以照著這個思路走,繼續做,所以后面會有InceptionV2,V3,V4等,它表現的結果也非常好。給我們傳統的通過堆疊層提高準確率的想法提供了一個新的思路。
作者:Charlotte77