輪廓
近年來,隨著自然語言處理,計算機視覺等領域的人工智能快速發展,公眾需要一個簡單有效的指標,幫助確定系統的人工智能和整個高性能。人工智能發展現狀。與此同時,良好的指標也可以在一個領域引發健康的可持續發展。
然而,傳統的高性能計算機評估方法和系統與當前人工智能的性能并不完全一致。例如,Linpack是一種高性能的計算機雙精度浮點計算性能基準評估程序,并且國際超級成本前500個列表根據臨床值排名,典型的人工智能應用不需要雙精度浮動觀點。手術。大多數人工智能訓練任務基于單精度浮點或半精密浮點數,原因是基于INT8。
對于大型人工智能,開發簡單有效的指標和測試方法并不容易。首先,大多數單一人工智能訓練任務(例如培訓推薦的系統或圖像分類的圖像分類)無法計算總機的計算要求。許多人工智能應用,即使他們使用全機尺寸,訓練時間和準確性也可能無法改善。其次,如果要測試手動智能群集計算機,則測試程序必須是可變的。首先,它必須清楚,可以任意調整哪種主流人工智能應用。最后,準確性的判斷和計算是大規模人工智能評估和傳統的基于高性能計算的評價之間的顯著差異。是否需要使剩余的剩余量小于給定的標準,是衡量分數統計的準確性,同樣需要清除。
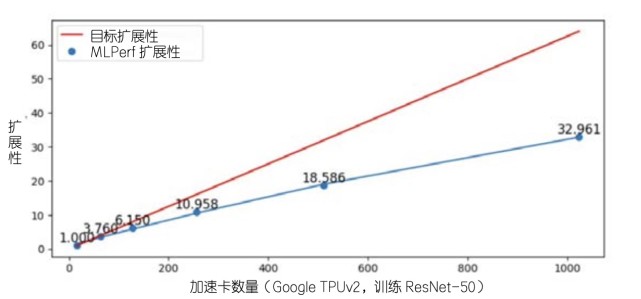
目前,主要公司,大學和相關組織在人工智能績效基準領域有很多探索,并開發了各種參考評估程序,如Mlperf,小米的Mobileai長凳,百度公司的深井,中國人工智能產業發展聯盟。 AIIA DNN基準和HPL-AI,基于雙重精密延長螺旋更換為混合精度。但這些參考測試程序不會很好地解決上述問題。根據MLPERF發布的數據,MLPERF程序將在多TPU加速器卡的規模中下降或更大,并且在數千個TPU加速卡水平上達到評估系統的可擴展性瓶頸。該評估過程難以評估不同的系統。規模尺度差異的差異。
Mlperf延伸瓶頸
AIPERF設計目標和想法
AIPERF是清華大學設計的人工智能參考測試程序,具有設計目標:
統一分數
參考測試程序應將分數作為評估指標報告,以評估群集系統。使用一個而不是多個分數來輕松比較不同的機器,并促進公眾的宣傳。此外,分數應隨著人工智能計算群集的規模增加線性生長,并且可以準確地評估不同系統中規模的差異。
2.可變問題量表
人工智能計算集群通常具有不同的系統規模,節點數量的差異反射,加速器數量,加速器類型,內存大小和其他指示器。因此,為了適應各種尺寸的高性能計算群集,預期的人工智能參考測試程序應該能夠通過問題的大小來適應簇大小的大小。使用人工智能計算計算資源以反映其實力。
3.有實際的人工智能
用人工智能計算,如神經網絡運營,是人工智能參考測試程序和傳統的高性能電腦參考測試的一個重要區別,也是檢測簇人工智能的核心。人工智能參考測試程序應基于當前流行的人工智能應用。
4.評估計劃包含必要的多機器通信
網絡通信是人工智能計算集群設計的主要指標之一,也是其巨大計算能力的重要組成部分。用于高性能計算集群的人工智能參考測試程序應包括必要的多機通信,從而使用網絡通信性能作為最終性能的影響因素之一。同時,參考測試程序中的多機通信模式應該具有典型的表示。