到處都是垃圾:人工智能太缺乏高質量的數據,
閱讀:來源|核心閱讀地圖來源:在一定程度上,人工智能已經超越了我們過去最大膽的想象;但在實踐中,Siri甚至不能告訴用戶今天的天氣如何。 有什么問題嗎? 創建高質量的數據庫來訓練和測量我們的模型仍然是一項極其困難的任務。 我們應該可以收集兩萬。。。 源|一天內核心閱讀

資料來源:光彩照人

在某種程度上,人工智能已經超越了我們過去最大膽的想象;但實際上,Siri甚至不能告訴用戶今天的天氣如何。
有什么問題嗎? 創建高質量的數據庫來訓練和測量我們的模型仍然是一項極其困難的任務。 我們應該能夠在一天內收集20000個標簽來訓練Reddit分類器,但是我們等待了三個月,得到了一個充滿垃圾郵件的訓練集。
《紐約時報》稱,四年前,AlphaGo擊敗了世界圍棋專家,大型科技公司為每一家他們能接觸到的機器學習初創企業購買了人才; 計算機技術
深層思維在2016年開始建立一個人工智能來玩星際爭霸2,到2019年底,人工智能項目“阿爾法星”(AlphaStar&rdquo)已經取得了巨大的成就。
看來幾年后,Alexa將占據我們的家園,Netflix將比我們的朋友提出更好的電影建議。
在那之后發生了什么?
更快的GPU放棄了訓練神經網絡消費,并允許不斷增長的模型被訓練。 新工具使基礎設施更容易工作。
還開發了新的神經網絡結構,可以學習運行更多的主觀任務。 例如,Open Ai GPT-3模式是一種語言生產者,可以撰寫博客文章,并從黑客新聞網站獲取標題。
一篇關于生產力GPT-3的博客文章成為黑客新聞的頭條。
那么改革是在哪里進行的呢?
那么人工智能為什么不占領世界呢? 為什么人們可以用GPT-3生成博客文章,但社交媒體公司很難從訂閱者中刪除煽動性內容? 為什么會有超人星際爭霸算法,但是電商還在推薦我再買一個嘔吐司機? 為什么模型可以合成逼真的圖片(和電影)但不能被識別?
模型正在進展中,數據仍處于停滯狀態。模型是在數據集上訓練的,數據集仍然有錯誤,并且很少與創建者真正想要表達的內容一致。
當前數據發生了什么? 來垃圾,去垃圾
在某些情況下,數據是基于類(如鏈接和用戶協議)對代理進行培訓的。
例如,社交媒體推文沒有經過培訓以提供最佳的用戶體驗;相反,它們只是充分利用鏈接和協議,這是獲取數據的最簡單方法。
但點贊數量與數量無關。 駭人聽聞的陰謀論非常引人注目,但你真的想在你的推特上看到它們嗎? 這種不匹配導致了許多意想不到的副作用,包括點擊誘餌的激增、廣泛的政治虛假信息和廣泛的惡意、煽動性內容。
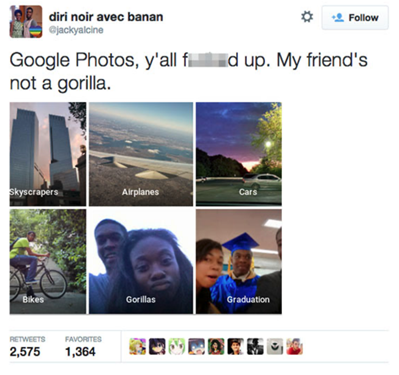
在其他時候,模型是在這樣的數據集上訓練的:由非母語使用者或知道低質量結果的人訓練的工作人員遠遠沒有被檢測到,而是創建數據集。 取以下推文:
一個典型的標記識別“婊子”,“他媽的”和“屎”并將這條推特標記為有害的,無論虐待是否基于積極、向上的態度。 這在訓練集中發生了無數次。 數據定義模型。 如果數據被錯誤標記為垃圾,沒有機器學習專家可以防止模型同樣無用。
我們需要什么樣的進步?
數據集問題造成了很多問題。
當面臨運行不良的模型時,工程師花了幾個月的時間來修復產品特性和新算法,而不知道它們的數據中存在問題。 本來應該用來凝聚感情和友誼的算法,相反,會帶來熾熱的情緒和憤怒的評論。 如何解決這些問題?
熟練和高質量的標記,理解你試圖解決的問題
雖然AI系統越來越復雜,但我們需要先進而巧妙的人類標記系統來教授和測量它們的性能。 想想那些了解世界的模型,足以對誤導性信息進行分類,或者增加時間而不是點擊的算法。
這種復雜性不會因為使用低技能工人而增加。 為了讓我們的機器理解仇恨言論和識別算法偏見,我們需要高質量的標簽力量,他們自己也理解這些問題。
空間供機器學習組和識別器進行交流
機器學習模型不斷變化。 今天的垃圾信息明天可能不一樣,我們永遠無法掌握密碼的每一個角落。
就像制造產品是一種用途一樣與工程師之間的反饋驅動過程一樣,數據集的創建也應該如此。 在數一幅畫中的面孔時,卡通人物是否計數? 在標記仇恨言論時,引號在哪里? 標記在瀏覽數千個示例后發現了歧義和洞察力,為了最大限度地提高數據質量,我們需要雙方進行溝通。
目標功能符合人類價值觀
模型通常被訓練在數據集上,這些數據集只是他們真正目標的近似,導致意想不到的分歧。
例如,在關于人工智能安全的辯論中,人們擔心機器智能發展到威脅世界的程度。 其他人反駁說,這是一個遙遠的未來的問題,然而,看看當今技術平臺面臨的最大問題,它不是已經發生了嗎?
例如,Facebook的使命不是獲得喜歡的東西,而是讓我們與朋友和家人聯系起來。但通過訓練他們的模型來增加偏好和互動,他們學會傳播具有高度吸引力的內容,但也可能是有害的和誤導的。
如果Facebook能將人類價值觀注入他們的培訓目標? 這不是幻想:谷歌搜索在其實驗中使用了人類評估,我們正在構建的人工智能系統致力于這樣做。
一個數據驅動的人工智能未來
在核心,機器學習是教計算機以我們想要的方式工作,我們通過展示積極的例子來實現我們的目標。 那么為了建立一個高質量的模型,機器學習工程師需要掌握的最重要的技能不應該是建立一個高質量的數據集,并確保它們與手頭的問題相匹配嗎?
最后,我們擔心人工智能是否能滿足人類的需求,而不是它是否超過人類的基準。
如果你在這里處理內容規則,您的數據集是否檢測到惡意語音,還是它也捕獲積極的、令人振奮的言語虐待?
如果您正在構建下一代搜索和推薦系統,您的數據集是設置模型的相關性和質量,還是誤導和吸引點擊是很吸引人的?
創建數據集不是學校里教的東西,花了多年研究算法的工程師很容易專注于arXiv中最花哨的模型。 但如果我們想要人工智能解決自己的實際需求,就需要對定義模型的數據集進行深入的思考,并賦予它們一定的人文色彩。
源|核心閱讀編譯|歐舒曼周婷
關于騰訊AI加速器
騰訊AI加速器是騰訊行業加速器的重要組成部分。依托騰訊AI實驗室矩陣核心技術,騰訊云平臺,計算能力以及合作伙伴豐富的應用場景,為選定的課程,技術,資本,生態,品牌等層面的項目提供支持。 并與入選項目一起打造行業解決方案,推動AI技術在行業的應用落地。
前兩個AI加速器期間,從全球2000項目中篩選出65個項目,整體估值662億,總融資達70億,70%的項目完成新一輪融資;其中騰訊投資樂聚機器人,工匠社會機器人,VersaMacaron播放圖片,并形成行業解決方案50。
162019年8月,騰訊AI加速器三期上市。 從1500個申請人中脫穎而出的TOP30項目,驗收率僅為2%,第三階段項目總估值超過200億。 該項目的重點是金融、教育、安全、工業、機器人、物聯網、云計算、5G等。 精選騰訊AI加速器第三期,意義正式成為騰訊智慧產業生態合作伙伴,將與騰訊各智慧產業業務深度結合。