從大數據到小數據,數據之坑與美

大數據雖然很火,但我們用數據發聲,用事實說話,大數據真的沒有那么普及,小數據目前還是主流。如果用“n=all”來代表大數據,那么就可以用“n=me”來說明小數據(這里n表示數據大小),我們將會看到,小數據更是關系到我們的切身利益。
美國著名科技歷史學家梅爾文 克蘭茲伯格(Melvin Kranzberg),曾提出過大名鼎鼎的科技六定律,其中第三條定律是這樣的[1]: 技術是總是配 套 而來的,但這個 套 有大有小(Technology comes in packages, big and small) 。
這個定律用在當下,是非常應景的。因為,我們正步入一個 大數據(big data) 時代,但對于以往的 小數據(small data) ,我們能做到 事了拂衣去,深藏身與名 嗎?答案顯然不是。目前,大數據的前途似乎 星光燦爛 ,但小數據的價值依然 風采無限 。克蘭茲伯格的第三定律是告訴我們,新技術和老技術的自我革新演變,是交織在一起的。大數據和小數據,他們 配套而來 ,共同勾畫數據技術(Data Technology,DT)時代的未來。
對大數據的 溢美之詞 ,已被舍恩伯格教授、涂子沛先生等先行者及其追隨者夸得泛濫成災。但正如您所知,任何事情都有兩面性。在眾人都贊大數據很好的時候,我們也需說道說道大數據可能面臨的陷阱,只是為了讓大數據能走得更穩。在大數據的光暈下,當漸行漸遠漸無小數據時,我們也聊聊小數據之美,為的是 大小并行,不可偏廢 。大有大的好,小有小的妙,如同一桌菜,哪道才是你的愛?思量三番再下筷。
下文部分就是供讀者 思量 的材料,主要分為4個部分:(1)哪個V才是大數據最重要的特征?在這一部分里,我們聊聊大數據的4V特征中,哪個V才是大數據最貼切的特征,這是整個文章的行文基矗(2)大數據的力量與陷阱。在這一部分,我們聊聊大數據整體的力量之美及可能面臨的3個陷阱。(3)今日王謝堂前燕,暫未飛入百姓家,在這一部分,我們要說明,大數據雖然很火,但我們用數據發聲,用事實說話,大數據真的沒有那么普及,小數據目前還是主流。(4)你若安好,便是晴天。在這一部分,我們說說的小數據之美,如果用 n=all 來代表大數據,那么就可以用 n=me 來說明小數據(這里n表示數據大小),我們將會看到,小數據更是關系到我們的切身利益。
1.哪個V才是大數據最重要的特征?
在談及大數據時,人們通常用4V來描述其特征,即4個以V為首字母的英文:Volume(大量)、Variety(多樣)、Velocity(速快)及Value(價值)。如果 閑來無事 ,我們非要對這4個V在 兵器譜 上排排名,哪個才是大數據的貼切的特征呢?下面我們簡要地說道說道,力圖說出點新意,分析的結果或許會出乎您的意料之外。
1.1 大 有不同 Volume(大量)
首先我們來說說大數據的第一個V Volume(大量)。雖然數據規模巨大且持續保持高速增長,通常作為大數據的第一個特征。但事實上,早在20年前,在當時的IT環境下,天文、氣象、高能物理、基因工程等領域的科研數據量,已是這些領域無法承受的 體積 之痛,當時實時計算的難度不比現在小,因為那時的存儲計算能力差,亦沒有成熟的云計算架構和充分的計算資源。
況且, 大 本身就是一個相對的概念,數據的大與小,通常都打著很強的時代烙櫻為了說明這個觀點,讓我們先回顧一下比爾 蓋茨的經典 錯誤 預測。
 圖1 比爾蓋茨于1981年對內存大小的預測
圖1 比爾蓋茨于1981年對內存大小的預測
早在1981年,作為當時的IT精英,比爾蓋茨曾預測說, 640KB的內存對每個人都應該足夠了(640KB ought to be enough for anybody) 。但30多年后的今天,很多人都會笑話蓋茨,這么聰明的人,怎么會預測地如此不靠譜,現在隨便一個智能手機(或筆記本電腦)的內存的大小都是4GB、8GB的。
但是,需要注意的事實是,在1981年,當時的個人計算機(PC)是基于英特爾CPU 8088芯片的,這種CPU是基于8/16位(bit)混合構架的處理器,因此,640KB已經是這類CPU所能支持的尋址空間的理論極限(64KB)的10倍[2],換句話說,640K在當時是非常非常地龐大了!再回到現在,當前PC機的CPU基本都是64bit的,其理論支持的尋址空間是2^64,而現在的4G內存,僅僅是理論極限的(2^32)/(2^64)= 1/(2^32)而已#
在這里,講這個小故事的原因在于,衡量數據大小,不能脫離時代背景,不能脫離行業特征。此外,大數據布道者舍恩伯格教授在其著作《大數據時代》中指出[3],大數據在某種程度上,可理解為 全數據(即n=all) 。有時,一個所謂的 全 數據庫,并不需要有以TB/PB計的數據。在有些案例中,某個 全 數據庫大小,可能還不如一張普通的僅有幾個兆字節(MB)數碼照片大,但相對于以前的 部分 數據,這個只有幾個兆字節(MB)大小的 全 數據,就是大數據。故此,大數據之 大 ,取義為相對意義,而非絕對意義。
這樣看來,互聯網巨頭的PB級數據,可算是大數據,幾個MB的全數據也可算是大數據,如此一來, 大數據之 大 大 有不同,可大可小,如此不 靠譜 ,反而不能算作大數據最貼切的特征。
1.2 數據共征 Velocity(快速) 與 Value(價值)
英特爾中國研究院院長吳甘沙先生曾指出,大數據的特征 Velocity(快速) ,猶如 天下武功,唯快不破 一樣,要講究個 快 字。為什么要 快 ?因為時間就是金錢。如果說價值是分子,那么時間就是分母,分母越小,單位價值就越大。面臨同樣大的數據 礦山 , 挖礦 效率是競爭優勢。
不過,青年學者周濤教授卻認為[4],1秒鐘算出來根本就不是大數據的特征,因為 算得越快越好 ,人類自打有計算這件事情以來,這個訴求就沒有變化過,而現在,卻把它作為一個新時代的主要特征,完全是無稽之談。 筆者也更傾向于這個說法,把一個計算上的 通識 要求,算作一個新生事物的特征,確實欠妥。
類似不妥的還有大數據的另外一個特征 Value(價值)。事實上, 數據即價值 的價值觀古來有之。例如,在《孫子兵法始計篇》中,早就有這樣的論斷 多算勝,少算不勝,而況于無算乎? 此處 算 ,乃算籌也,也就是計數用的籌碼,它講得就是,如何利用數字,來估計各種因素,從而做出決策。
在馬陵之戰中,孫臏通過編造 齊軍入魏地為十萬灶,明日為五萬灶,又明日為三萬灶(史記 孫子吳起列傳) 的數據,利用龐涓的數據分析習慣,反其道而用之,對龐涓實施誘殺。
話說還有一個關于林彪將軍的段子(真假不可考),在遼沈戰役中,林大將軍通過分析繳獲的短槍與長槍比例、繳獲和擊毀小車與大車比例,以及俘虜和擊斃的軍官與士兵的比例 異常 ,因此得出結論,敵人的指揮所就在附近!果不其然,通過追擊從胡家窩棚逃走的那部分敵人,活捉國民黨主帥新六軍軍長廖耀湘。
在戰場上,數據的價值 就是輔助決策來獲勝。還有一點值得注意的是,在上面的案例中,戰場上的數據,神機妙算的軍師們,都能 掐指一算 這顯然屬于十足的小數據!但網上卻流傳有很多諸如 林彪也玩大數據 、 跟著林彪學習大數據 等類似的文章,這就純屬扯淡了。如果凡是有點數據分析思維的案例,都歸屬于大數據的話,那大數據的案例,古往今來,可真是數不勝數了。
因此,Value(價值)實在不能算是大數據專享的特征, 小數據 也是有價值的。在下文第4節的分析中,我們可以看到,小數據對個人而言, 價值 更是不容小覷。這樣一來,如果大、小數據都有價值,何以 價值 成為大數據的特征呢? 事實上,睿智的IBM,在對大數據的特征概括中,壓根就沒有 Value 這個V(如圖2所示)。
 圖2 IBM公司給出的大數據3V特征(圖片來源:disquscdn.com)
圖2 IBM公司給出的大數據3V特征(圖片來源:disquscdn.com)
我們知道,所謂 特征 者,乃事物異于它物之特點 。打個比方,如果我們說 有鼻子有眼是男人的特征 ,您可能就會覺得不妥: 難道女人就沒有鼻子沒有眼睛嗎? 是的, 有鼻子有眼 是男人和女人的 共征 ,而非 特征 。同樣的道理,Velocity 和Value這兩個V字頭詞匯,是大、小數據都能有的 共征 , 實在也不算不上是大數據最貼切的特征。
1.3五彩繽 紛 Variety(多樣)
通常認為,大數據的多樣性(Variety),是指數據種類多樣。其最簡單的種類劃分,莫過于分為兩大類:結構化的數據和非結構化數據,現在 非結構化數據 占到整個數據比例的70%~80%。早期的非結構化數據,在企業數據的語境里,可以包括諸如電子郵件、文檔、健康、醫療記錄等非結構化文本。隨著互聯網和物聯網(Internet of things,IoT)的快速發展,現在的非結構化數據又擴展到諸如網頁、社交媒體、音頻、視頻、圖片、感知數據等,這詮釋了數據的形式多樣性。
但倘若深究下去,就會發現, 非結構化 未必是個成立的概念。在信息中, 結構化 是永存的。而所謂的 非結構化 ,不過是某些結構尚未被人清晰的描述出來而已。IT咨詢公司Alta Plana的高級數據分析師Seth Grimes曾在IT領域著名刊物《信息周刊》(Information Week)撰文指出:不存在所謂的非結構化,現在所說的 非結構化 ,應該是非模型化(unmodeled),結構本在,只是人們處理數據的功力未到,未建模而已(Most unstructured data is merely unmodeled)[5](如圖3所示)。
 圖3 Seth Grimes:非結構化乎,不!應是非建模
圖3 Seth Grimes:非結構化乎,不!應是非建模
大數據的多樣性(Variety),還體現在數據質量的參差不齊上。換句話說,這個語境下的多樣性就是混雜性(Messy),即數據里混有雜質(或稱噪音)。大數據的混雜性,基本上是不可避免的,既可能是數據產生者在產生數據過程出現了問題,也可能是采集或存儲過程存在問題。如果這些數據噪音是偶然的,那么在大數據中,它一定會被更多的正確數據淹沒掉,這樣就使得大數據具備一定的容錯性;如果噪音存在規律性,那么在具備足夠多的數據后,就有機會發現這個規律,從而可有規律的 清洗數據 ,把噪音過濾掉。吳甘沙先生認為[15],多元抑制的數據,能夠過濾噪聲、去偽存真,即為辯訛。更多有關混雜性的精彩描述,讀者還可批判性地參閱舍恩伯格教授的大著《大數據時代》[3]。
事實上,大數據的多樣性(Variety),最重要的一面,還是表現在數據的來源多和用途多上。每一種數據來源,都有其一定的片面性和局限性,只有融合、集成多方面的數據,才能反映事物的全貌。事物的本質和規律隱藏在各種原始數據的相互關聯之中。對同一個問題,不同的數據能提供互補信息,可對問題有更為深入的理解。因此在大數據分析中,匯集盡量多種來源的數據是關鍵。中國工程院李國杰院士認為[6],這非常類似于錢學森老先生提出的 大成智慧學 , 必集大成,才能得智慧 。
著名歷史學家許倬云先生,站在歷史的高度,也給出了自己的觀點,他說 大數據 之所以能稱之為 大數據 ,就在于,其將各種分散的數據,彼此聯系,由點而線,由線而面,由面而層次,以瞻見更完整的覆蓋面,也更清楚地理解事物的本質和未來取向。
英國數學家及人類學家托馬斯 克倫普(Thomas Crump)在其著作《數字人類學》(The Anthropology of Numbers)指出[7],數據的本質是人,分析數據就是在分析人類族群自身,數據背后一定要還原為人。東南大學知名哲學教授呂乃基先生認為[8],雖然每個數據來源因其單項而顯得模糊,然而由 無限的模糊 所帶來的聚焦成像,會比 有限的精確 更準確。 人是社會關系的總和(馬克思語) 。大數據利用自己的 多樣性 ,比以往任何時候都趨于揭示這樣的 總和 。
因此,李國杰院士認為[6],數據的開放共享,提供了多種來源的數據融合機會,它不是錦上添花的事,而是決定大數據成敗的必要前提。
從上分析可見,雖然大數據有很多特征(甚至有人整出11個V來),但大數據的多樣性(Variety),無疑它是區分以往小數據的最重要特征。
2. 大數據的力量與陷阱
大數據的多樣性,給大數據分析帶來了龐大的力量,但這個多樣性也帶來了大數據的陷阱,下面我們就聊聊這個話題。
2.1 大數據的力量
很多小概率、大影響的事件(即黑天鵝事件),在單一的小數據環境下,很可能難以發現。但是由 八方來客 匯集而來的大數據,卻能有機會提供更為深刻的洞察(insight)。例如,癌癥屬于一類長尾病癥,經過多少年努力,癌癥治愈率僅提升了不到8%。其中一個重要原因是,單個癌癥的診療機構的癌癥基因組樣本都相對有限。 小樣本 得出的研究結論,得出有關 癌癥診斷 的結論,極有可能是 盲人摸象化 的[9]。
于是,英特爾公司提出的 數據咖啡館 概念,吳甘沙先生做了一個形象的類比,他說咖啡館的好處在于 Let ideas have sex ,而大數據產生價值、爆發力量的關鍵是 Let data have sex 。取意如此,數據咖啡館 的核心理念在于,把不同醫療機構的癌癥診療數據匯聚到一起,形成大數據集合,但不同機構間的數據, 相逢但不相識 。讓多源頭的 小數據 匯集起來,可實現數據之間 1+1>2 的價值。對多數據融合用 have sex 這個比喻,是非常有意思的,因為倘若你真想要達到 1+1> 2 的效果,就不能帶著 套子 擋著,就要打破 數據流的割據 。難怪李院士一直強調,數據的流通性,是決定大數據成敗的前提,還是真的(純屬調侃,不可較真)!
類似的,2014年美國總統辦公室發布了題為 大數據:抓住機遇,留住價值(Big data:Seizing Opportunities, Preserving Values) 的報告[10],文中列舉了一個案例:
Broad 研究院(這是一個由麻省理工學院和哈佛大學聯合創辦的世界著名的基因研究機構)的研究人員發現,海量的基因數據,在識別遺傳變異對疾病的意義中,有著及其重要的作用。在這個研究中,當樣本數量是 3,500 時,與精神分裂癥有關的遺傳變異,根本無法檢測出來;當使用 10,000 個樣本時,也只能有細微的識別;但是當樣本達到 35,000 時,統計學上的統計顯著性(statistically significant)便突然顯示出來。正如一個研究人員所觀察到的那樣, 跨越拐點,一切皆變!(There is aninflection point at which everything changes) [11](如圖4所示)。從這個案例中,大數據把哲學中的 量變引發質變 演繹得淋漓盡致。
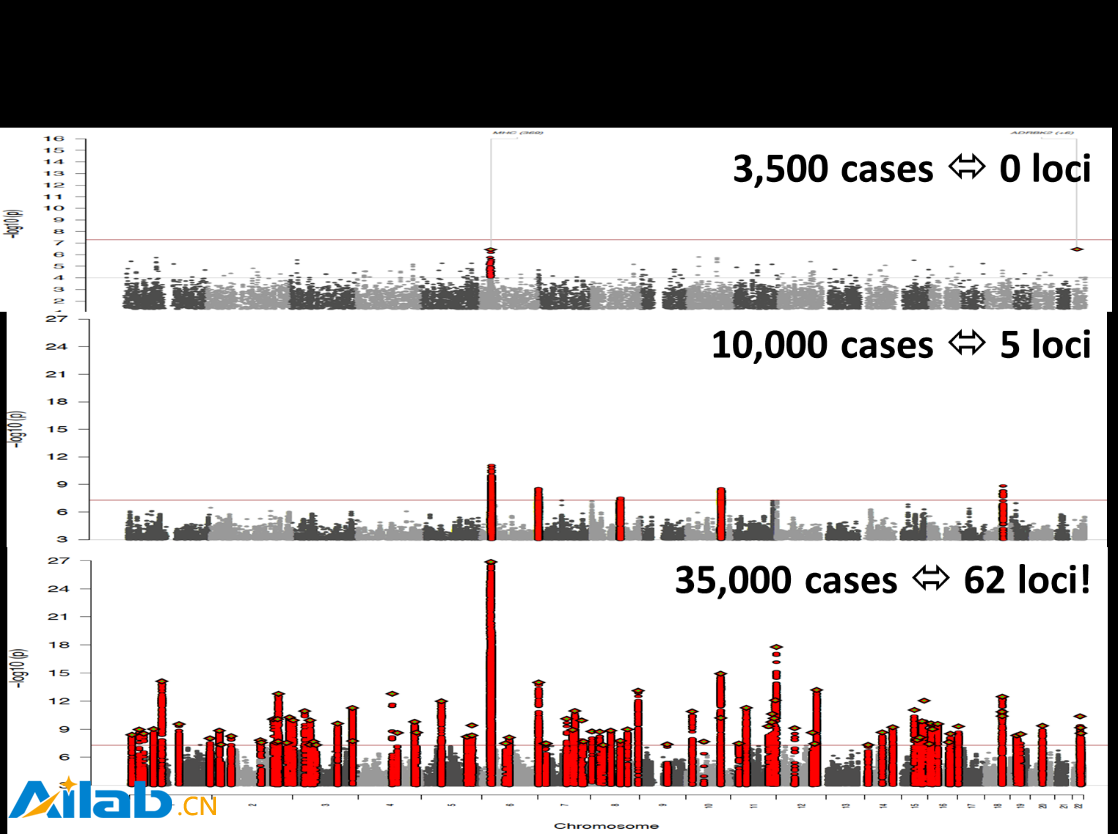 圖4 精神分裂癥有關的遺傳變異發現 大數據的 匯集 的力量(圖中loci表示 基因座 ,又稱座位,它基因在染色體上所占的位置。在分子水平上,是有遺傳效應的DNA序列。圖片來源:MIT)
圖4 精神分裂癥有關的遺傳變異發現 大數據的 匯集 的力量(圖中loci表示 基因座 ,又稱座位,它基因在染色體上所占的位置。在分子水平上,是有遺傳效應的DNA序列。圖片來源:MIT)
2.2 大數據的陷阱
大數據的多樣性,帶人們來了 兼聽則明 的智慧。然而,正如英諺所云: 一個硬幣有兩面(Every coin has two sides) , 這個多樣性也會帶來一些不宜察覺的 陷阱 。用 成也蕭何,敗也蕭何 來描述大數據的兩難,再恰當不過了。
2.2.1 DIKW金字塔體系
1989年,管理學家羅素 艾可夫(Russell .L. Ackoff)撰寫了《從數據到智慧》(From Data to Wisdom),系統地構建了DIKW體系[12],即從低到高依次為數據(Data)、信息(Information)、知識(Knowledge)及智慧(Wisdom)。美國學者澤萊尼(Zeleny)提出了4個Know(知道)比喻[12],比較形象地區分了DIKW體系中的元素,如圖5所示。
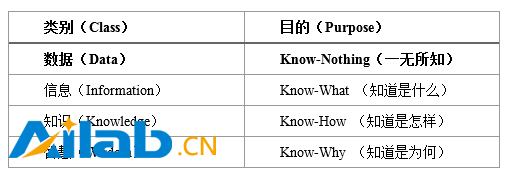 圖5 澤萊尼對DIKW體系中的4個Know比擬
圖5 澤萊尼對DIKW體系中的4個Know比擬
澤萊尼對DIKW體系的注解,讓人感觸最深的可能在于,數據如果不實施進一步地處理,即使收集數據的容量再 大 ,也毫無價值,因為僅僅就數據本身,它們是 一無所知(Know-Nothing) 的。數據最大的價值,在于形成信息,變成知識,乃至升華為智慧。
舍恩伯格教授在其大作《大數據時代》有個核心觀點是: 要相關,不要因果 ,即知道 是什么 就夠了,沒必要知道 為什么 。但從DIKW體系可知,如果放棄 為什么 的追尋,事實上,就放棄了對金字塔的最頂端 智慧(Wisdom)的追求 而智慧正是人類和機器最本質的區別。
對此,青年學者周濤教授總結得非常精彩: 放棄對因果性的追求,就是放棄了人類凌駕于計算機之上的智力優勢,是人類自身的放縱和墮落。如果未來某一天機器和計算完全接管了這個世界,那么這種放棄就是末日之始 。對大數據的因果性和相關性的探討,我們已經在《來自大數據的反思:需要你讀懂的10個小故事》一文中[14],已有涉及,在此不再贅言,下面我們想探討的是,事實上,對因果關系的追尋,是人類慣有的思維,在這個慣性思維推動下,很容易誤把 相關 當 因果 這是我們需要警惕的大數據陷阱。
2.2.2 誤把 相關 當 因果
所謂 相關性 是指兩個或兩個以上變量的取值之間存在某種規律性。兩個變量A和B有相關性,只反映A和B在取值時相互有影響,但并不能說明因為,有A就一定有B,或者反過來因為有B就一定有A。
在上面的論述中,似乎我們一直在說 相關性 的不足。而事實上,需要說明的是,相關性在很多場合是極其有用的。例如,在大批量的小決策上,相關性就是有用的,亞馬遜的電子商務個性化推薦,就是利用相關性,給無數顧客推薦相關的或類似商品,這樣顧客找起商品方便多了,亞馬遜也落得個賺得缽滿盆滿。
然而,對于小批量的大決策,對因果關系的追求,依然是非常重要的。吳甘沙先生用 中西藥 藥方做類比,給出了一個很精彩的例子,用來說明相關性和因果性的關系[15]。對于中藥處方而言,多是 神農嘗百草 式的經驗處方,目前僅僅到達知道 相關性 這一步,但它沒有可解釋性,無法得出是那些樹皮和蟲殼的因,為什么就是導致某些病能治愈的果,換句話說,中藥僅僅到了 知其然 階段(追求 是什么 ),如果我們的國粹止步于 知其所以然 (追求 為什么 ),那么中醫想要走出中國,面向世界,是非常困難的(注:筆者曾是中醫的受益者,請不要誤判是在黑中醫)。
而西藥則不同,在發現相關性后,并沒有止步,而是進一步要做隨機對照試驗,把所有可能導致 治愈的果 的干擾因素排除,獲得因果性和可解釋性。在商業決策上也是類似,相關性只是決策的開始,它取代了拍腦袋、依靠直覺獲得的假設,而后面驗證因果性的過程仍然是重要。
在大數據時代, 相關性 被很多大數據粉絲奉為圭臬。前文也提到, 相關性 也的確有用,但有時,人們會不自覺地把 相關性 不自覺地當作 因果性 。
加拿大萊橋大學管理學院鮑勇劍教授指出[16],在大數據時代,只要有超大樣本和超多變量,我們都可能找到無厘頭式的相關性。美國政府每年公布4.5萬類經濟數據。如果你要找失業率和利率受什么變量影響,你可以羅列10億個假設。只要你反復嘗試不同的模型,上千次后,你一定可以找到統計學意義上成立的相關性。下面我們講幾個小故事(段子)來說明這個觀點。
在小數據時代的1992年,香港人拍了一個電視連續劇《大時代》,其中著名演員鄭少秋飾演丁蟹,丁蟹是一個資深的股民,股海翻騰,身心疲憊,終無所得。在1992年的隨后20多年里,只要電視臺一播放鄭少秋主演的連續劇,香港恒生指數都會有不同程度的下跌,人稱 丁蟹效應(或稱秋官效應) ,這是有樣本支持的,如圖6所示。每次鄭少秋主演的電視劇播放預告時,總有香港股民打電話到電視臺,希望不要播放,因為擔心虧錢。
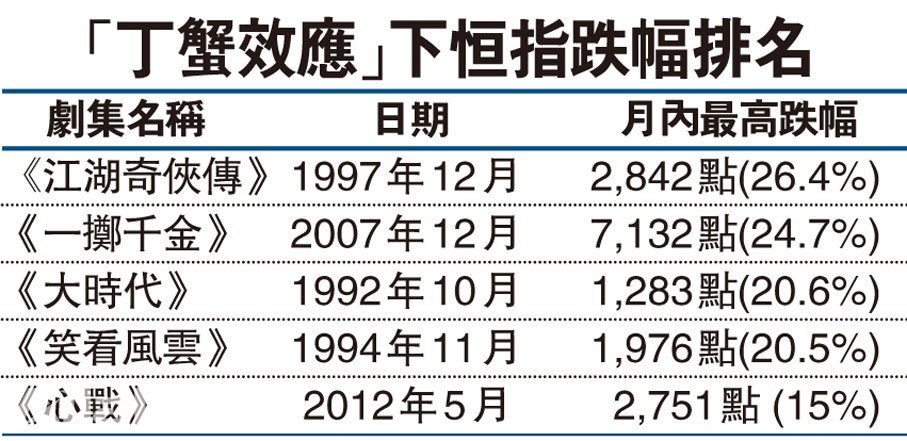 圖6 丁蟹效應與香港股市(圖片來源:文匯報)
圖6 丁蟹效應與香港股市(圖片來源:文匯報)
更無厘頭的是,這相關性還扯到中國運動員劉翔身上了,下面是個 余溫尚存 段子,它是這樣描述的:
2008年8月18日 北京奧運會,劉翔因傷退賽,當天股市大跌5.3%,并且一個月內大跌20%。
2014年9月他宣布結婚一個月后,股市就開始狂漲,從2300點漲到5178點。
2015年6月26日,劉翔離婚,股市繼續大跌至8%。股市的漲跌原來都是因為劉翔啊!
因此,網友們強烈要求劉翔盡快宣布再次結婚。
香港的股民為什么不希望鄭少秋主演的電視劇播放,是因為怕電視劇一播放,股市就下跌。大陸的股民為什么希望劉翔再次結婚,因為劉翔有喜了,所以股市就有喜了。注意到前面描述中體現出來的 因果關系 嗎?
事實上,《大時代》和劉翔和股市之間有何因果關系?不過是樣本大了,變量多了,統計上的 相關性 就會冒出來而已。而人們卻 潛移默化 地把觀察到的 相關 ,當作事物背后的 因果 。
或許,就有人不太認可上述觀點,認為上面兩個小故事,都是屬于段子級別的案例,何以能說明問題?那我們就舉一個古而有之的案例來說明這個觀點。請讀者略看下面的文字:
黃梅時節家家雨,青草池塘處處蛙。
潮起潮落勁風舞,夏夜夏雨聽蛙鳴。
荷沐夏雨嬌滴滴,稻里蛙鳴一片歡。
夏雨涼風,蟬噪蛙鳴,熱浪來襲,遠處云樹晚蒼蒼。
皇阿瑪,你還記得當年蛙鳴湖邊的夏雨荷嗎?
我們知道,文學雖然高于生活,但亦源于生活。從上面的從古至今的 文人墨客 的詩情畫意中,讀者依稀可看出一點點相關性 人類祖先經過長期觀察發現,蛙鳴與下雨往往是同時發生。這樣的長期觀察樣本,也可稱得上是 大數據 。于是,在久旱無雨的季節,不求甚解的古人,就會把這個 相關性 當作 因果性 了,他們試圖通過學蛙鳴來求雨。在多次失靈之后,就會走向巫術、獻祭和宗教[8](如圖7所示)。因此,同小數據一樣,在大數據中,可解釋性(因果關系)始終是重要的。
 圖7 印度人民以蛙求雨的習俗,源遠流長,至今留存(圖片來源:互聯網)
圖7 印度人民以蛙求雨的習俗,源遠流長,至今留存(圖片來源:互聯網)
博弈論創始人之一、天才計算機科學家諾伊曼(John von Neumann)曾戲言稱: 如果有四個變量,我能畫頭大象,如果再給一個,我讓大象的鼻子豎起來! 大數據的來源多樣性,變量復雜性,為誕生 新穎 的相關性,創造無限可能。而本質上,人們對因果關系的追求,事實上,已經根深蒂固,這種思維慣性難以輕易改變,而在大數據時代,會面臨著冒出更多的相關性, 亂花漸欲迷人眼 。大數據的擁躉者們說, 要相關,不要因果 ,但事實上,在很多時候,特別是人們在對未來無法把控的時候,很容易把 相關 當作 因果 !這是大數據時代里一個很大的陷阱,特別值得注意。
2.2.3 大數據的其它陷阱
下面,我們用另外一個小 故事 來說明大數據的第二個陷阱:
假如你是一位出車千次無事故的好司機,年關將近,酒趣盎然,在朋友家喝了點小酒,這時估計警察也該下班過年了,于是你堅持自己開車回家,盤算著這酒后駕車出事故的概率也不過千分之一吧。如果這樣算,你就犯了一個取樣錯誤,因為前一千次出車,你沒喝酒,它們不能和這次 酒后駕車 混在一起計算(故事來源:參考文獻[16])。
這是大數據分析中的第二個容易跳入的陷阱。大數據的多樣性里,包括了數據質量上的 混雜性 ,某些低頻但很重要的弱信號,很容易被當作噪音過濾掉了!從而痛失發現 黑天鵝 事件的可能性。
再例如,在美國,學習飛機駕駛是件 司空見慣 的事,在幾十萬學習飛機駕駛的記錄中,如果美國有關當局能注意到,有那么幾位學員只學習 飛機起飛 ,而不學習 飛機降落 ,那么9/11事件或許就可以避免,世界的格局可能就此發生根本性的變化(當然,這個事件也為中國贏得了10年的黃金發展期,不在本文的討論范圍,就不展開說)。在大數據時代的分析中,很容易放棄對精確的追求,而允許對混雜數據的接納,但過多的 混雜放縱 ,就會形成一個自設的陷阱。因此,必需 未雨綢繆 ,有所提防。
在大數據時代里,第三個值得注意的陷阱是,大數據的擁躉者認為,大數據可以做到 n=all (這里n數據的大小),因此無需采樣,這樣做也就不會再有采樣偏差的問題,因為采樣已經包含了所有數據。但事實上, n=all 很難做到,統計學家們花了200多年,總結出認知數據過程中的種種陷阱(如統計偏差等),這些陷阱不會隨著數據量的增大而自動填平。
3.今日王謝堂前燕,暫未飛入百姓家 大數據沒那么普及!
目前,雖然大數據被炒得火熱,甚至連股票交易大廳的大爺大媽都可以聊上幾句 大數據 概念股,但是大數據真的有那么普及嗎?
事實上,倘若想要充分利用大數據,至少要具備3個條件:(1)擁有大數據本身;(2)具備大數據思維;(3)配備大數據技術。這三個高門檻,事實上,已經把很多公司企業拒之門外,套用劉禹錫那句詩:今日王謝堂前燕,不入尋常百姓家 大數據依然還是那么高大上,遠遠沒有那么普及!
圖8所示的是,著名IT咨詢公司高德納(Gartner)于2014年公布的技術成熟度曲線(hype cycle)。國內將 hype cycle 翻譯成 成熟度曲線 ,實在是太過文雅了,直譯為 炒作周期 也毫不為過。從圖8可以看出,大數據已經過了炒作的高峰期,目前處于泡沫化的底谷期 (Trough of Disillusionment)。
在歷經前面的科技誕生促動期 (Technology Trigger)和過高期望峰值期(Peak of Inflated Expectations)這兩個階段,泡沫化的底谷期存活下來的科技(如大數據),需要經過多方歷練,技術的助推者,要么咬牙堅持創新,要么無奈淘汰出局,能成功存活下來的技術及經營模式,將會更加務實地茁壯成長。
李國杰院士在接受《湖北日報》的采訪時,也表達了類似的觀點, 大數據剛剛過了炒作的高峰期 [17]。冷靜下來的大數據,或許可以走得更遠。
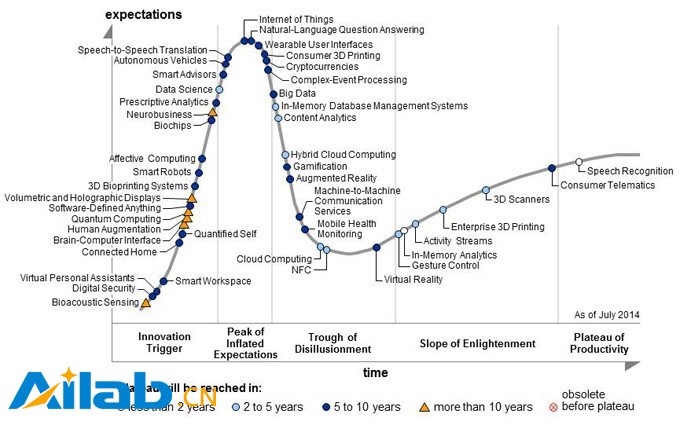 圖8 高德納技術成熟度曲線(圖片來源:Gartner)
圖8 高德納技術成熟度曲線(圖片來源:Gartner)
李國杰院士還表示,大數據與其他信息技術一樣,在一段時間內遵循指數發展規律。指數規律發展的特點是,在一段時期衡量內(至少30年),前期發展慢,經過相當長時間(可能需要20年以上)的積累,會出現一個拐點,過了拐點以后,就會出現爆炸式的增長。但任何技術都不會永遠保持 指數性 增長,最后的結局,要么進入良性發展的穩定狀態,要么走向消亡。
大數據的布道者們,張口閉口言稱大數據進入PB時代了。例如,《連線》雜志的前主編克里斯 安德森早在2008年說: 在PB時代,數量龐大的數據會使人們不再需要理論,甚至不再需要科學的方法。 但是這個吹捧也是非常不靠譜的,亦需要潑冷水還有大數據。
在大數據時代,我們要習慣讓數據發聲。下面的統計數據來自大名鼎鼎的學術期刊《科學》(Science)。2011年,《科學》調查發現[18],在 你科研過程中使用的(或產生的)最大數據集是多少? 的問卷調查中(如圖9所示),48.3%的受訪者認為他們日常處理的數據小于1GB,只有7.6%的受訪者說他們日常用的數據大于1TB(1TB=1024GB,1PB=1024TB),也就是說,調查數據顯示,92.4%用戶所用的數據小于1TB,一個稍微大點的普通硬盤就能裝載得下,這讓那些動輒言稱PB級別的大數據的布道者們情何以堪啊?而大數據重度鼓吹手IDC,目前正在為業界巨擘搖旗吶喊ZB時代(1ZB=1024PB),我們一定要冷眼看世界,慢慢等著瞧吧!
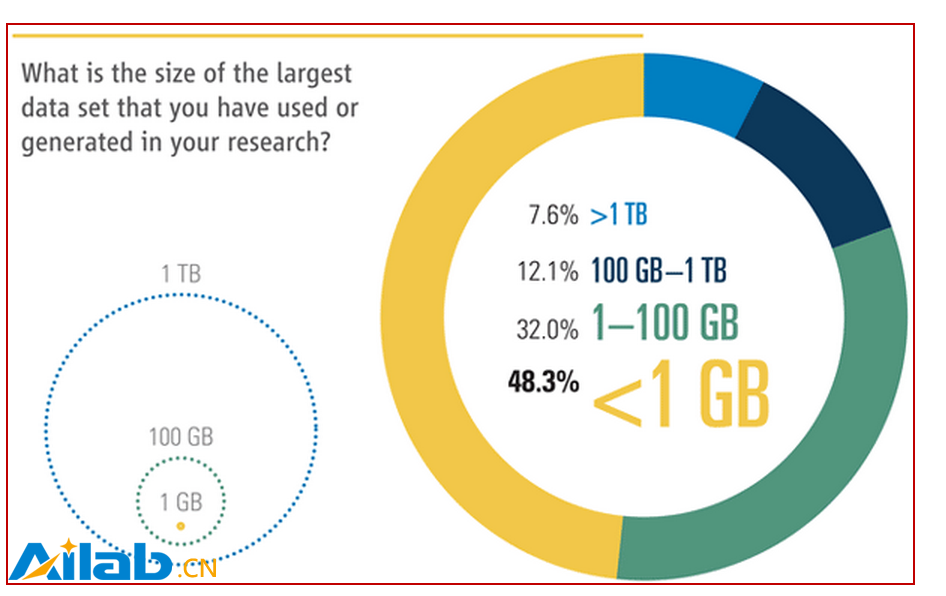 圖9 在你的科研中,你使用的(或產生)最大數據集是多大?(圖片來源:科學期刊)
圖9 在你的科研中,你使用的(或產生)最大數據集是多大?(圖片來源:科學期刊)
而在 你在哪里存儲實驗室產生的數據或科研用的數據? 問卷調查中,50.2%的受訪者回答是在自己的實驗室電腦里存儲,38.5%受訪者回答是在大學的服務器上存儲。由此可見,大部分的數據依然處于數據孤島狀態,在數據流通性的道路是,依然 路漫漫其修遠兮 。而數據的流通性和共享性,如前文所述,是大數據成敗的前提。
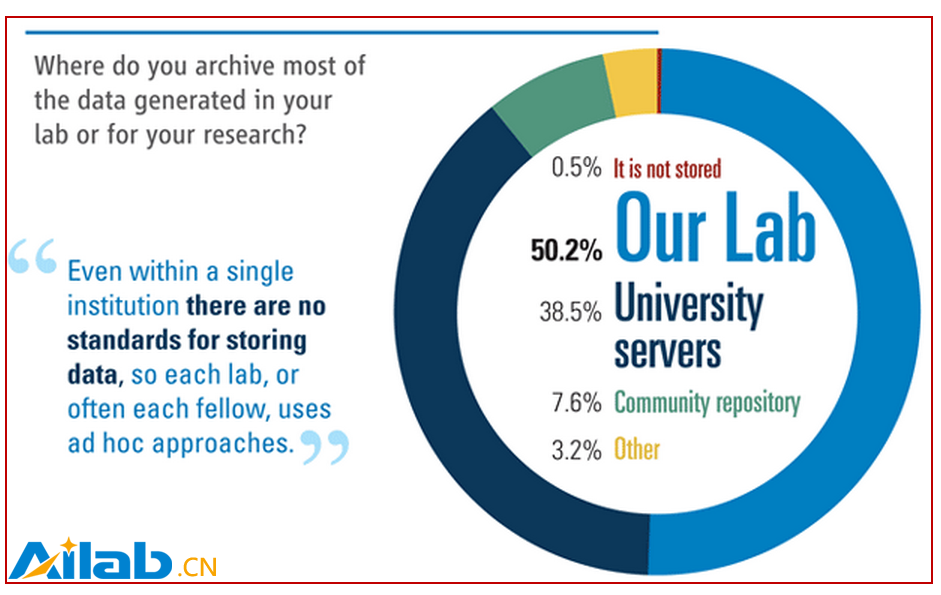 圖10 你主要在哪里存儲你實驗產生的或科研數據?(圖片來源:科學期刊)
圖10 你主要在哪里存儲你實驗產生的或科研數據?(圖片來源:科學期刊)
或許也有讀者不以為然,說我就是屬于那部分小于7.6%的人(即使用或產生的數據大于1TB)。 我小眾,我自豪 ,此類信心滿滿的人,大多來自主流的互聯網公司,如Google、Yahoo、微軟、Facebook等,而在國內的自然非BAT莫屬了。事實上,即使來自這類大公司的日常業務,其數據集也不是那么大的 觸目驚心 。
微軟研究院資深研究員Antony Rowstron等人撰文指出[19],根據微軟和Yahoo的統計,所有Hadoop的作業放一起,取個中間值,其輸入數據集的大小也不過是14GB。即使是在大數據大戶Facebook,其90%的作業輸入數據集,也是小于100GB的(clusters (at Microsoft and Yahoo) have median job input sizes under 14 GB, and 90% of jobs on a Facebook cluster have input sizes under 100 GB)。那些動輒拿某個互聯網巨頭的數據體積總和,來 忽悠 大家的大數據布道者們,更應該借給受眾們 一雙慧眼 ,讓他們 把這紛擾看得清清楚楚明明白白真真切切 。
當然,Antony Rowstron的這篇論文 意不在此 ,文中的主要訴求是,既然我們日常處理的數據沒有那么大到 不成體統 ,就沒有必要把某臺機器的性能指標一味地縱向擴展(scale up),比如把內存從8G升級為16GB,32GB,64GB,甚至更高,而是應該選擇更加 經濟實惠 的橫向擴展(Scale out)策略,比如將若干個8GB低配置的機器連接在一起,組成一個廉價的集群(cluster),然后利用Hadoop將集群用起來,所以這篇論文的標題是 沒有人會因在集群上使用Hadoop而被解雇(Nobody ever got fired for using Hadoop on a cluster) ,言外之意,在目前大數據語境下,使用 類Hadoop(Hadoop-like) 工具分析大數據是未來主流的趨勢之一,就業市場一片光明。
從上面的分析可以看出,我們不否認,大數據是前沿,但我們更不能對目前的現狀熟視無睹 小數據依然是主流。目前大多數公司、企業其實仍處于 小數據 處理階段。但只要在縱向上有一定的時間積累,在橫向上有較豐富的記錄細節,通過多個源頭對同一個對象采集的各種數據有機整合,實施合理的數據分析,就可能產生大價值。基于此,李國杰院士指出,在大數據時代,我們是不能拋棄 小數據 的[9]。
對精確的追求,歷來是傳統的小數據分析的強項,這在一定程度上彌補大數據的 混雜性 缺陷。猶如有句歌詞唱得那樣: 結識新朋友,不忘老朋友 。在大數據時代,我們也不能忘記小數據。大數據有大數據的力量,小數據有小數據的美。下面我們就聊聊這個話題。
4.你若安好,便是晴天 小數據之美
小數據,其實是大數據的一個有趣側面,是其眾多維度的一維。有時,我們需要大數據的全維度可視,周濤教授甚至把 全息可見 作為大數據的特征,而這個特征在對用戶數字 畫像 時,非常有用,因為這樣做,非常有利于商家推廣 精準營銷 。
在這里,我們再次強調托馬斯 克倫普的哲學觀 數據的本質是人。技術也是為人服務的。對于 普羅大眾 而言,有時,我們并不希望自己被數字化,被全息透明化,這就涉及到個人隱私問題了。如果大數據技術侵犯個人的隱私,讓受眾不開心了,那這個技術就應該有所限制和規范,但這不在本文的討論范圍,就不展開說了。
流行的 大數據 定義是: 無法通過目前主流軟件工具在合理時間內采集、存儲、處理的數據集 。我們很容易反其道而用之,定義出 小數據(small data) , 通過目前主流軟件工具可以在合理時間內采集、存儲、處理的數據集 。這就是傳統意義上的小數據,經典的數理統計和數據挖掘知識,可以較好地解決這類問題。這個范疇的小數據,屬于老生常談,所以本文不談。
我們下文討論的小數據,是一類新興的數據,它是圍繞個人為中心全方位的數據,是我們每個個體的數字化信息,因此,也有人稱之為 iData 。這類小數據跟大數據的根本區別在于,小數據主要以單個人為研究對象,重點在于深度,對個人數據深入的精確的挖掘,對比而言,大數據則側重在某個領域方面,在大范圍、大規模全面數據收集處理分析, 側重在于廣度。
小數據是大數據的某個側面,事實上,很多時候,對于個人而言,這個所謂的側面就有可能是特定個人的全面。當大數據受萬人矚目時,創新技術(如智能手機、智能手環及智能體育等)也讓小數據 個人的自我量化(Quantified Self,QS), 面朝大海,春暖花開 。
個人量化,可以測量、跟蹤、分析我們日常生活中點點滴滴。比如,今天的早餐我攝入了多少卡路里?圍著操場跑一圈我消耗了多少熱量,在手機的某個App(如微信)上我耗費了多少時間?等等諸如此類。在某種程度上,是小數據,而非大數據,才是我們生活的幫手。 小數據 不比大數據那樣浩瀚繁雜,卻對我自己至關重要。下面我們用兩個小案例來說明小數據的應用。
先說一個稍微高大上的案例。據科技記者Emily Waltz在IEEE Spectrum的撰文指出[20],目前佩戴在運動員身上生物小配件(Biometric gadget,通常指傳感器),正在改變世界精英級運動員的訓練方式。這些可穿戴傳感器設備,提供實時的生理參數,而在以前,倘若要獲取這樣的數據,需要笨重和昂貴的實驗室設備。如同40年前,風靡一時的負重訓練方案,可讓運動員更有韌性,可穿戴裝備能幫助運動員提高成績并同時避免受傷。一些棒球手、自行車運動員和橄欖球等競技運動員用新裝備尋求優勢。
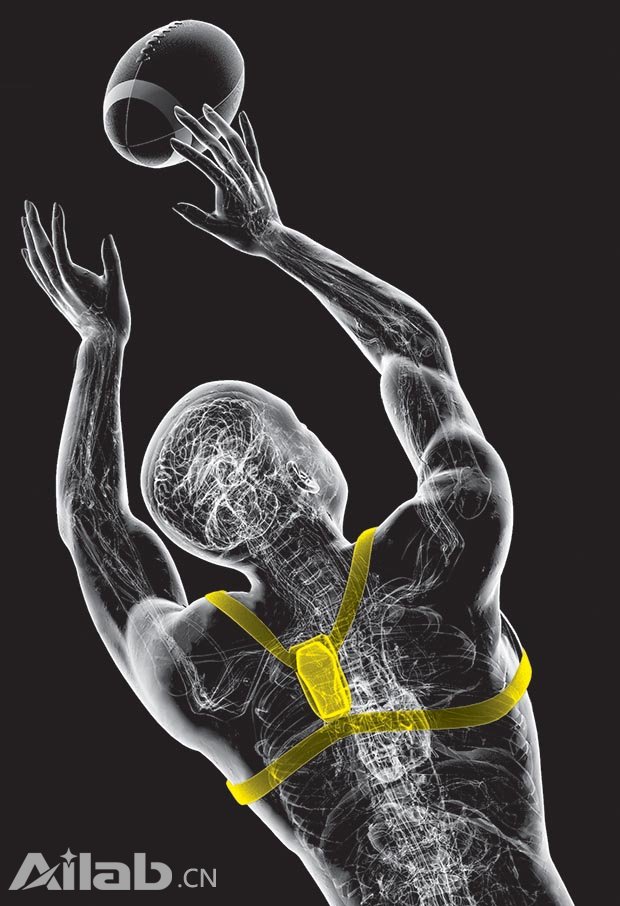 圖11 運動員利用可穿戴設備訓練美式橄欖球(圖片來源:IEEE)
圖11 運動員利用可穿戴設備訓練美式橄欖球(圖片來源:IEEE)
例如,在如圖11所示的裝備中,運動員身上的傳感器能夠精確記錄在室內外場館的運動特征。這些自我量化設備,可放置于運動員背部的壓縮衣中,它能夠監控運動員的加速、減速、方向改變以及跳躍高度和運動距離等指標。教練員能夠通過監控數據,來檢測每個運動員訓練強度,并防止過度訓練所帶來的傷害。這些自我量化設備的工作原理是,協同使用很多小設備,如加速計、磁力計、陀螺儀、GPS接收儀等 這些設備每秒能夠產生100個數據點。通過無線連接,計算機可以實時采集這些數據。個人量化分析軟件,可對運動特征和特定位置實施分析,計算機專家系統中的算法,可以檢測到運動員在做對了什么、做錯了什么,基于此,教練可以給出更加有針對性的訓練。目前此類設備的使用者,包括一半以上的NFL(橄欖球聯盟)、三分之一的NBA運動員、一半以上的英超球隊以及世界各地的足球隊、橄欖球隊和劃船運動隊等。
自我量化設備(可穿戴設備)通常是和物聯網(Internet of things,IoT)是有關聯的。而現在還處于炒作巔峰的物聯網(如圖8所示),通常是和大數據扯到一起的,但是就某個具體的物聯網設備而言,它一定先是產生少量的甚至是微量的數據,也就是說,物聯網首先是小數據,然后才能匯集成大數據。沃頓商學院教授、紐約時報最佳暢銷書作者喬納 伯杰(Jonah Berger)推測[21],個人的自我量化數據,或許將會是大數據革命中下一個演進方向。由此可見,大、小數據之間并無明顯的界限。再大的數據也是人們一點一滴聚沙成塔、集腋成裘的。沒有小數據的積少成多、百川歸海,大數據也是無源之水、無本之木。
但如同中國那句老話說的, 一屋不掃,何以掃天下 ,如果小數據都不能很好地處理,如何來很好地處理 匯集 而來的大數據?
說完高大上的案例,下面我們再聊聊一個 平淡無奇 生活小案例[22]:
故事的主人是美國康奈爾大學教授德波哈爾 艾斯汀(Deborah Estrin)。Estrin的父親于2012年去世了,而早在父親去世之前的幾個月里,這位計算機科學教授就注意到一些 蛛絲馬跡 , 相比從前,父親在數字社會脈動(social pulse)中,已有些許變化 他不再查閱電子郵件,到附近散步的距離也越來越短,也不去超市買菜了。
然而,這種逐漸衰弱的跡象,在他去醫院進行的常規心臟病(cardiologist)體檢中,不一定能看出來。不管是測脈搏,還是查病歷,這位90歲的老人都沒有表現出特別明顯的異常。可事實上,倘若追蹤他每時每刻的個體化數據,這些數據雖小,但也足夠刻畫好出,老人的生活其實已然明顯與之前不同。
這種日常自我量化的小數據,帶來了生命訊息的警示和洞察,啟發了這位計算機科學教授,促使Estrin在康奈爾大學創建創建了 小數據實驗(the small data lab @CornellTech,訪問鏈接:http://smalldata.io/) 。在Estrin看來,小數據可以看作是一種新的醫學證據,它僅是 他們的數據中屬于你的那一行(your row of their data) [23] 。
舍恩伯格教授在其著作《大數據時代》中,將大數據定義為全數據(即n=All,n為數據的大小),其旨在收集和分析與某事物相關的 全部 數據。類似的, Estrin將小數據定義為: small data where n=me ,它表示,小數據就是全部有關于我(me)的數據[24]。
如此一來,可以看出,小數據更加 以人為本 ,它可以為我們提供更多研究的可能性:能不能通過分析年老父母的集成數據,進而獲得他們的健康信息?能不能通過這些集成數據,比較不同的醫學治療方案?如果這些能實現, 你若安好,便是晴天 ,便不再是一句空洞的 文藝腔 ,而是一席 溫情脈脈 的期望。
人,是一切數據存在的根本。人的需求是所有科技變革發展的動力。可以預見,不遠的將來,數據革命下一步將進入以人為本的小數據的大時代。當然,這并非說大數據就不重要。一般來說,從大數據得到規律,用小數據去匹配個人。吳甘沙先生用《一代宗師》的臺詞來比擬大、小數據的區分,倒也甚是恰當。他說,小數據 見微 ,作個人刻畫,可用《一代宗師》中 見自己 形容之;而大數據 知著 ,反映自然和群體的特征和趨勢,可用《一代宗師》中的 見天地、見眾生 比喻之。
著名科技史學家馬爾文 克蘭茲伯格(Melvin Kranzberg)提出的 克蘭茲伯格第一定律 指出, 技術既無好壞,亦非中立 ,即技術確實是一種力量,但 與社會生態技術的相互作用,使得技術發展經常有問題,遠遠超出了技術設備的直接目的和實踐自己的環境,人類釋放出來的技術力量與人類本身互動的復雜矩陣,都是有待探索的問題,而非必然命運 。
前面我們說道大數據可能存在數據安全及隱私問題,事實上,小數據同樣存在類似的問題,甚至更為嚴峻。我們應清楚,諸如大數據、小數據的科技,既可以為公眾謀福利,也可能對人造成傷害。關鍵就是,如何在機遇與挑戰間尋找到最佳的平衡。
5.小結
在數據的江湖里,既有波瀾壯闊的大數據,也有細流漣漪的小數據,二者相輔相成,才能相映生輝。美國電子電氣工程師協會會士(IEEE Fellow)、中國科學院計算技術研究所研究員閔應驊表示[25]:目前大數據流行,人們就 言必稱大數據 ,這不是做學問的態度,不要碰到大量的數據,就給它戴上一頂帽子 大數據 。目前,各行各業碰到的數據處理多數還是 小數據 問題。不管是大數據還是小數據,我們應該敞開思想,研究實際問題,切忌空談,精準定位碰到的數據業務問題,以應用為導向,而非以技術為導向,不要哪個技術熱,追逐哪個。
《Fierce Big Data》編輯Pam Baker表明[26],當你在尋思如何抉擇大數據,還是小數據時,先擱置這事兒。思量一下,你的公司是否擅長利用數據創造價值,如果你的公司還沒有達到這個境界,那先把這事解決了再說。
前中信銀行行長、中信集團監事長朱小黃也曾說[27]: 數據本無大小,但運用數據的立場卻分大小,是謂大數據 。深以為然。
在京劇《沙家浜》有句經典唱詞: 壘起七星灶,銅壺煮三江。擺開八仙桌,招待十六方 。如果大數據、小數據是這 八仙桌 上的菜,來自 十六方 的您,在下口之前,一定要先確定,哪道才是你的菜,不然花了冤枉錢,還沒有吃好,那可就 整個人都不好了 。
參考文獻
[1]Kranzberg, Melvin . Technology and History: "Kranzberg's Laws", Technology and Culture, Vol. 27, No. 3, pp. 544 560. 1986
[2] Eric Lai.The '640K' quote won't go away -- but did Gates really say it?
[3]維克托 邁爾 舍恩伯格, 肯尼思 庫克耶. 盛楊燕,周濤譯.大數據時代[M].浙江人民出版社.杭州,2013
[4] 周濤.什么是大數據?科學網博客. http://blog.sciencenet.cn/blog-3075-603325.html
[5] Seth Grimes. InformationWeek. Structure, Models and Meaning : is "unstructured" data merely unmodeled?
[6] 李國杰. 對大數據的再認識[J]. 大數據, 2015, 1(1): 2015001.
[7] Thomas Crump. The Anthropology of Numbers (Cambridge Studies in Social and Cultural Anthropology) .Cambridge University Press, 1992
[8]呂乃基. 大數據與認識論[J]. 中國軟科學, 2014, (9):34-45. DOI:10.3969/j.issn.1002-9753.2014.09.004.
[9] Bernard Marr.大數據專家Bernard Marr:大數據是如何對抗癌癥的?CSDN. http://www.csdn.net/article/2015-07-14/2825204/1
[10] Executive Office of the President . Big data:Seizing Opportunities, Preserving Values, May 2014
[11] Manolis Kellis, importance of Access to Large Populations, Big Data Privacy Workshop: Advancing the State of the Art in Technology and Practice, Cambridge, MA, March 3, 2014.
[12] Ackoff, Russell (1989). "From Data to Wisdom". Journal of Applied Systems Analysis 16: 3 9.
[13] Zeleny, M. "From knowledge to wisdom: On being informed and knowledgeable, becoming wise and ethical." International Journal of information technology & decision making 5.04 (2006): 751-762.
[14] 張玉宏.來自大數據的反思:需要你讀懂的10個小故事, CSDN. http://www.csdn.net/article/2015-07-28/2825312/1
[15] 吳甘沙.漫談大數據的思想形成與價值維度,2014
[16] 鮑勇劍.第一財經日報.大數據的陷阱 為什么小數據更重要?
[17] 湖北日報.李國杰:大數據剛剛過了炒作的高峰期. 2015-3-30
[18] Challenges and Opportunities. Science. 11 February 2011: Vol. 331 no. 6018 pp. 692-93 DOI: 10.1126/science.331.6018.692.
[19]Rowstron A, Narayanan D, Donnelly A, et al. Nobody ever got fired for using Hadoop on a cluster[C]//Proceedings of the 1st International Workshop on Hot Topics in Cloud Data Processing. ACM, 2012: 2.
[20] Emily Waltz. The Quantified Olympian: Wearables for Elite Athletes. http://spectrum.ieee.org/biomedical/devices/the-quantified-olympian-wearables-for-elite-athletes. 28 May 2015.
[21] Jonah Berger. Is Little Data The Next Big Data? https://www.linkedin.com/pulse/20130908184001-5670386-is-little-data-the-next-big-data
[22] Jonah Comstock . Why small data, data donation should be healthcare s future. http://mobihealthnews.com/21681/why-small-data-data-donation-should-be-healthcares-future/ . Apr 17, 2013
[23]Valerie Barr.The Frontier of Small Data. Communications of the ACM .http://cacm.acm.org/blogs/blog-cacm/168268-the-frontier-of-small-data/fulltext. September 29, 2013
[24] Estrin D. Small data, where n= me[J]. Communications of the ACM, 2014, 57(4): 32-34.
[25] Pam Baker.Small data vs big data: the battle that never was. Fierce Big Data.http://www.fiercebigdata.com/story/small-data-vs-big-data-battle-never-was/2014-06-02
[26] 閔應驊.大數據時代聊聊小數據.《北京青年報》. 2014年04月16日http://zqb.cyol.com/html/2014-04/16/nw.D110000zgqnb_20140416_3-11.htm
[27] 涂子沛. 數據之巔: 大數據革命, 歷史, 現實與未來[M]. 中信出版社, 2014.
作者介紹:張玉宏,博士。2012年畢業于電子科技大學,現執教于河南工業大學。中國計算機協會(CCF)會員,ACM/IEEE會員。主要研究方向為高性能計算、生物信息學,主編有《Java從入門到精通》一書。本文原題:大數據,小數據,哪道才是你的菜?