與機器人對話:初探語音智能交互
 2023-07-10 04:00:14
2023-07-10 04:00:14

我們經常能在科幻影片里能看到各種機器人與人類同臺出演,與人類自由的溝通交流,甚至比人類更加聰明。大家肯定想知道這樣的人造機器是如何做到的,我們現在真的能造出這樣的機器人嗎?
開玩笑,我在這絕不可能解釋好這個問題,但是從另一個角度簡單來講,與機器人交流其實這是通過語音來實現與機器交互,互動的一種操作,人與機器人的溝通其核心的一個方面便是語音的識別,就是說機器人得先聽懂人說話。那此文就來淺聊下關于通過語音來實現人機交互的一些問題。
我們先看一個較簡單的例子 —— Windows語音識別程序:

Windows語音識別功能主要是使用聲音命令指揮你的電腦,實現離開鍵盤鼠標來實現人機交互。通過聲音控制窗口、啟動程序、在窗口之間切換,使用菜單和單擊按鈕等功能。Windows語音識別功能僅僅限于 Windows系統體系內的一些常用操作和指令,并且是與監視器顯示輔助來完成整個語音操作。
例如你想用語音通過主菜單打開某個程序,當你說出“開始”后,系統將會提供一個“顯示編號”的區塊劃分功能,(編號是半透明的,使你能知道此編號下是哪個程序或文件夾)這樣假如你想打開“下載”這個文件夾,你只需說出它的編號“10”,程序就會給你打開“下載”這個文件夾了。這樣做的原因一是因為:如果你需要開啟用戶自行安裝的紛繁復雜的程序,Windows的語音庫里面可能沒有這些程序相應的名稱,會造成識別不準,甚至無法識別,二是通過顯示編號,和語音識別編號,響應指令的效率更高,因此這樣語音配合監視器的分模塊顯示大大的提高了用戶使用Windows系統的效率和準確率。
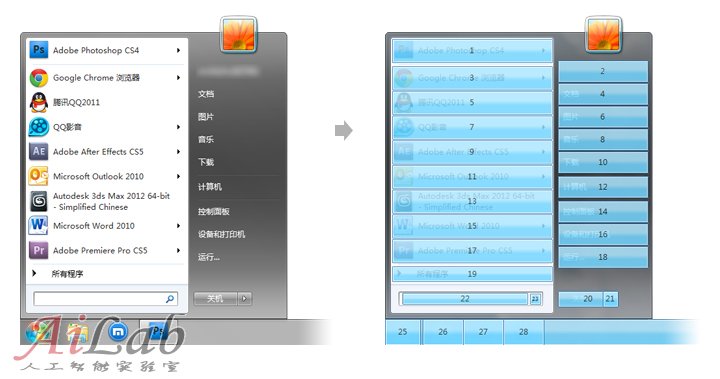
同樣,如果你對桌面的快捷方式或文件進行語音操作,系統將會提供一個稱之為“鼠標網絡”的功能,對桌面進行以前區域的劃分和自動編號,用語音+視覺來提高操作效率和識別的精準率:
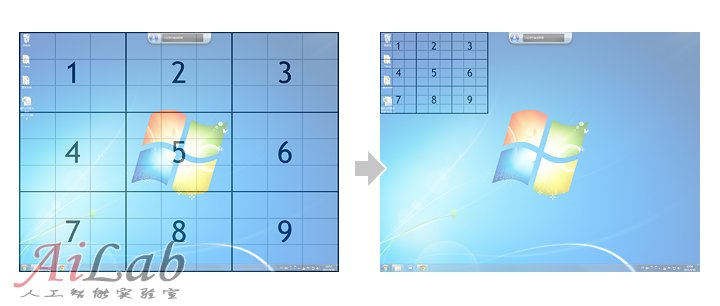
在目前Windows的語音識別程序中,除文本的語音輸入(包括文字和符號)之外,還包括16個常用命令,9項常用控件命令,31項文本處理命令,15項窗口命令,5個點擊屏幕任意位置命令,以及另外的幾組鍵盤命令。用戶所能語音指揮的也就是圍繞這些預先準備好了的命令進行交互操作,旨在這將有可能提高使用電腦的效率,和盡可能的把雙手從鼠標鍵盤上解放出來。
與此初衷相類似的我們還能在目前主流的移動設備上能看到語音識別功能的應用:
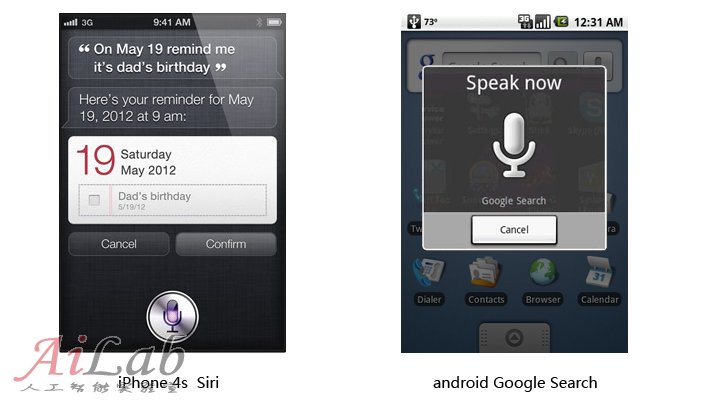
然后我們在前進一點,再想一下假如現在我們要面對的不是電腦,手機,而是一個機器人!一位擬人化,仿真化的機器人,對比上面的例子你會很容易發現它和常用的電子設備的不同之處在于,它很可能是不會有一個我們通常所見的顯示屏,那以上那些通過語音指令結合屏幕可視化輔助來進行的高效的交互方式在機器人身上就收到了限制。在這種情況下你面對著機器人,你肯定會想它在聽我說話嗎?它能聽懂我說話嗎?我說什么它能聽懂?我說什么它可能聽不懂?等等這樣一對問題會立即撲面而來。
其實在我們現有的技術水平和條件下,特別是面向大眾商用的機器人,想做到像電影里面那種人和機器人自由交流的情景幾乎是不可能。當然我們做一個產品,當然會有功能定位和市場需求等等很多方面要考慮的,那我在這里討論的是一臺為用戶提供各種咨詢和能進行簡單語音邏輯“聊天”的機器人,需要如何處理語音交互方面的問題,這里以Qrobot為例,盡可能不依賴電腦屏幕,而直接來與人互動和提供各種咨詢的機器人。
人是上帝創造的,而機器人是由人創造的,在現有知識和技術條件下,在人類賦予他特定的能力之前,機器人是什么也做不了的。下面我將分幾點來討論要想實現與機器人交互溝通需要做哪些工作:
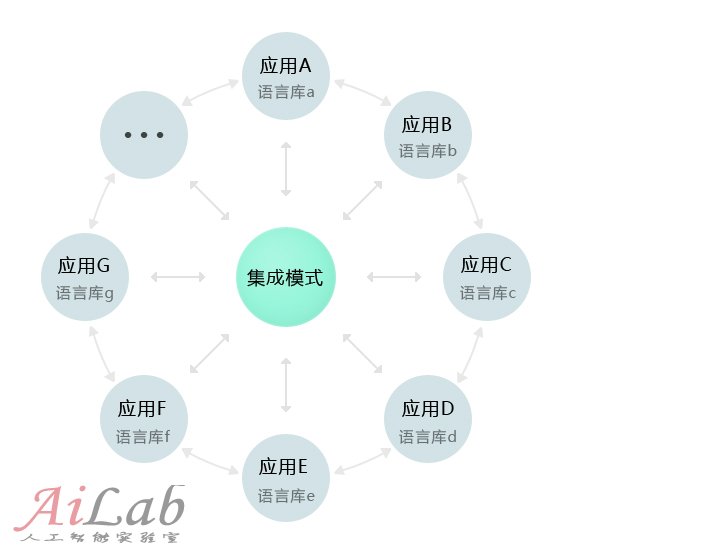
一,給機器人提供一個“大腦”—— 思想的材料:知識、語言庫。像Qrobot這樣提供各種海量咨詢和交流操作功能的機器人,如果把所有的這些“原材料”堆在一堆,一旦你有求于它的時候,它可能會慌了手腳,不知所云。(機器人無法根據對話的前后關系以及語境來判斷某一個詞在當前情境下恰當的含義)因此我們先會把機器人的語音知識庫進行分類,把不同類型和專業的詞語庫分開來,以提高機器人的工作效率和服務的準確度。那這樣用戶如需要獲得哪方面的信息和功能,就要先讓機器人“思維”進入相應的語言庫中。比如你通過機器人來了解“音樂”方面的信息的時候,你需要讓機器人進入音樂相關的“語庫思維”中,那在這個情況下它會把你說的任何話當作“音樂”相關的內容或指令了。
這里對比下蘋果最近發布的iPhone 4s 的Siri,根據資料分析來看Siri是一個集中統一的語音分析處理中心,它通過監聽用戶語音,然后提取關鍵詞來理解用戶意圖,(當然用戶事先要知道iPhone能幫他做些什么)然后可能經過跟你確認,再觸發相應的功能和服務。因此它最終提供功能咨詢和服務來自于整個iPhone系統不論是本地Apps或是云端(網絡APIs)已經準備整合好了的咨詢信息及功能。這樣的處理方式能使產品看起來更加的聰明和易用。
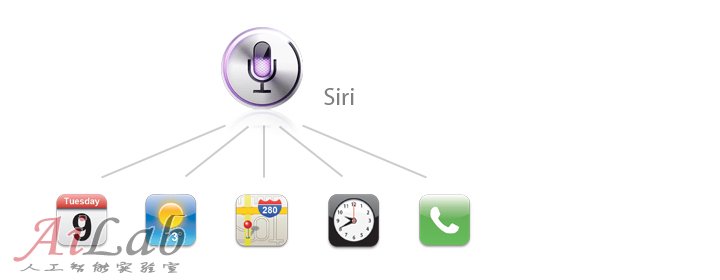
當然除了被分區的專業語庫外,機器人還得有個“正常人”的思維,即識別專業語言庫以外的各種指令和普通對話,(上圖的集成模式)否則的話它將只能是“機器”而無“人”了。